
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
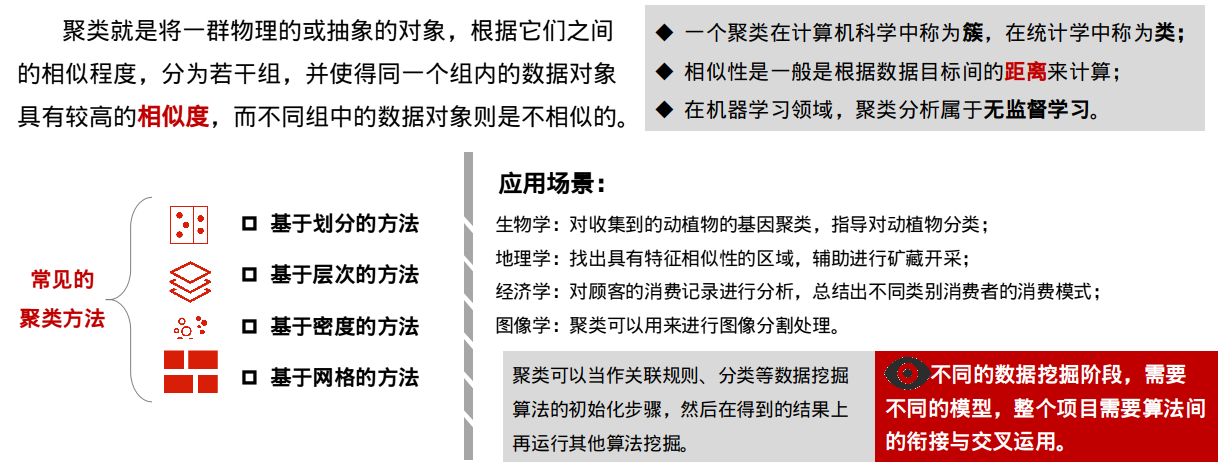
航空公司客户价值分析(聚类分析)

业务背景及目的
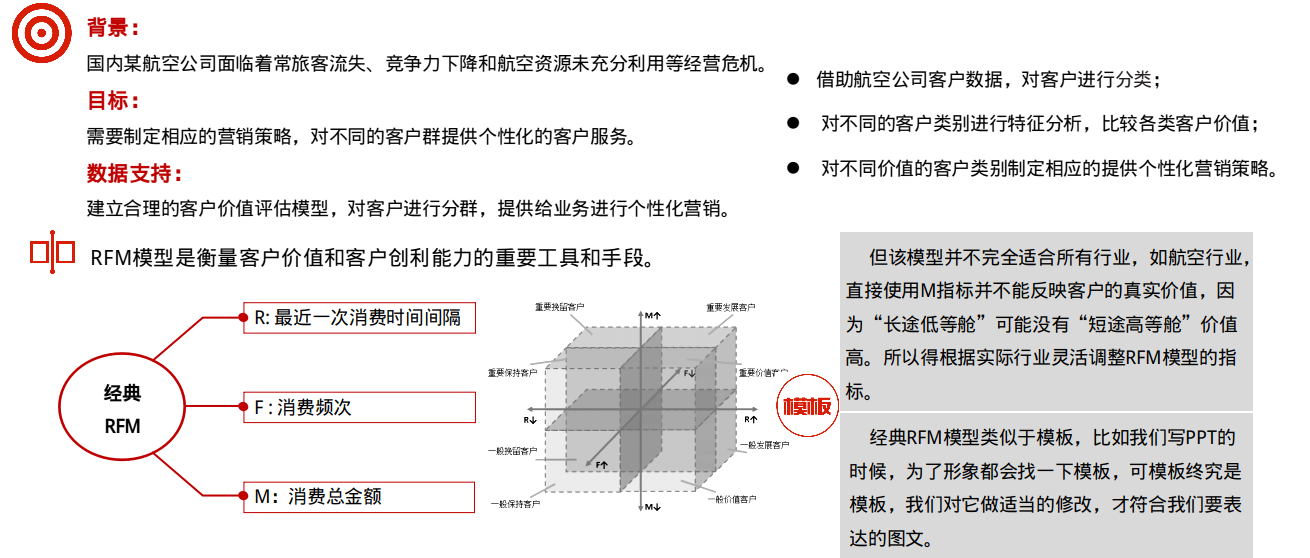
序号 | 属性 | 说明 | 序号 | 属性 | 说明 |
1 | MEMBER_NO | 会员卡号 | 23 | LAST_TO_END | 客户最近1次乘机距观测窗口结束时间间隔 |
2 | FFP_DATE | 入会时间 | 24 | AVG_INTERVAL | 平均乘机时间间隔 |
3 | FIRST_FLIGHT_DATE | 首次飞行时间 | 25 | MAX_INTERVAL | 最大乘机时间间隔 |
4 | GENDER | 性别 | 26 | ADD_POINTS_SUM_YR_1 | 第1年其他积分(合作伙伴、促销、外航转入) |
5 | FFP_TIER | 会员卡等级 | 27 | ADD_POINTS_SUM_YR_2 | 第2年其他积分(合作伙伴、促销、外航转入) |
6 | WORK_CITY | 城市 | 28 | EXCHANGE_COUNT | 积分兑换次数 |
7 | WORK_PROVINCE | 省份 | 29 | avg_discount | 舱位等级对应的平均折扣系数 |
8 | WORK_COUNTRY | 国家 | 30 | P1Y_Flight_Count | 第1年乘机次数 |
9 | AGE | 年龄 | 31 | L1Y_Flight_Count | 第2年乘机次数 |
10 | LOAD_TIME | 观测窗口结束时间(下载时间) | 32 | P1Y_BP_SUM | 第1年基本积分 |
11 | FLIGHT_COUNT | 乘机飞行次数 | 33 | L1Y_BP_SUM | 第2年基本积分 |
12 | BP_SUM | 总基本积分 | 34 | EP_SUM | 总精英积分 |
13 | EP_SUM_YR_1 | 第1年总精英积分 | 35 | ADD_Point_SUM | 其他积分总和(合作伙伴、促销、外航转入) |
14 | EP_SUM_YR_2 | 第2年总精英积分 | 36 | Eli_Add_Point_Sum | 非乘机积分总和 |
15 | SUM_YR_1 | 第1年票价收入 | 37 | L1Y_ELi_Add_Points | 第2年非乘机积分总和 |
16 | SUM_YR_2 | 第2年票价收入 | 38 | Points_Sum | 总累计积分 |
17 | SEG_KM_SUM | 总飞行公里数 | 39 | L1Y_Points_Sum | 第2年总累计积分 |
18 | WEIGHTED_SEG_KM | 总加权飞行公里数 | 40 | Ration_L1Y_Flight_Count | 第2年的乘机次数比率(两年内) |
19 | LAST_FLIGHT_DATE | 最后1次乘机时间 | 41 | Ration_P1Y_Flight_Count | 第1年的乘机次数比率(两年内) |
20 | AVG_FLIGHT_COUNT | 平均飞行次数 | 42 | Ration_P1Y_BPS | 第1年里程积分占最近两年积分比例 |
21 | AVG_BP_SUM | 平均基本积分 | 43 | Ration_L1Y_BPS | 第2年里程积分占最近两年积分比例 |
22 | BEGIN_TO_FIRST | 入会距离第1次登记的时间长度 | 44 | Point_NotFlight | 非乘机的积分变动次数 |
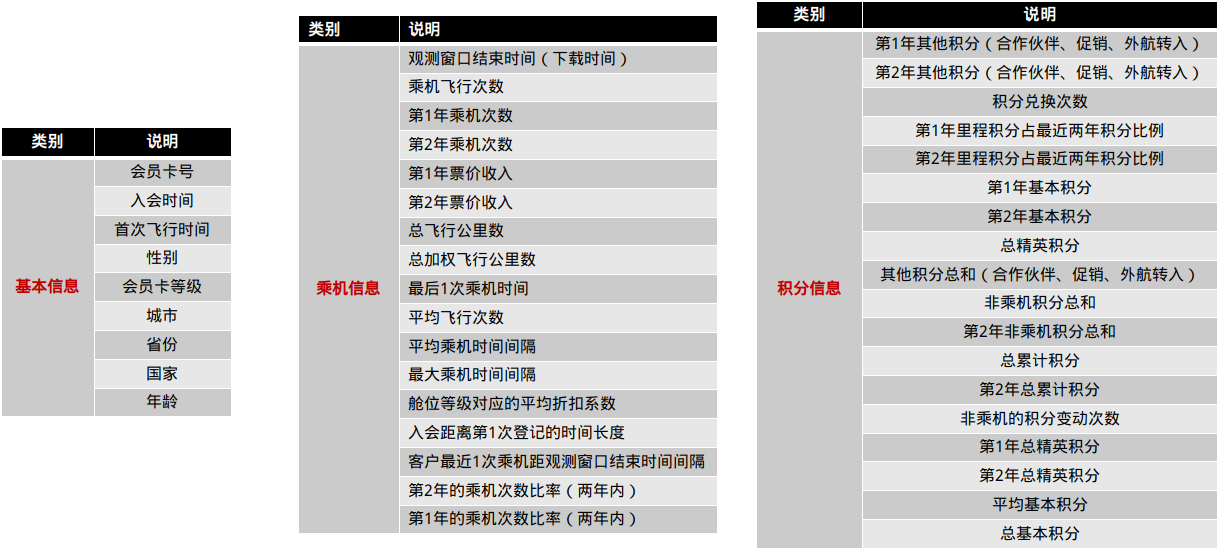

#设定工作空间
getwd()
#安装包
#install.packages("rpart")
#install.packages("rpart.plot")
#install.packages("RGtk2")
install.packages("rattle")
#加载包
library(rpart)
library(rattle)
library(rpart.plot)
#导入数据
yizhi<-read.csv(file="决策树案例.csv")
#查看数据集描述
summary(yizhi)
str(yizhi)
head(yizhi)
#数据类型转换
yizhi$cfps_gender<-as.factor(yizhi$cfps_gender)
yizhi$cfps_latest_edu<-as.factor(yizhi$cfps_latest_edu)
yizhi$pa301<-as.factor(yizhi$pa301)
yizhi$qg406<-as.factor(yizhi$qg406)
yizhi$qg17<-as.factor(yizhi$qg17)
yizhi$qp605_s_1<-as.factor(yizhi$qp605_s_1)
yizhi$qq501<-as.factor(yizhi$qq501)
str(yizhi)
#训练集与测试集
set.seed(1234)
ind<-sample(2,nrow(yizhi),replace =TRUE,prob=c(0.7,0.3))
yizhi_train<-yizhi[ind==1,]
yizhi_test<-yizhi[ind==2,]
summary(yizhi_train)
#CART主要参数设置
rc <- rpart.control(minsplit=20,minbucket=20,maxdepth=10,xval=5,cp=0.005)
#建立CART决策树模型以及模型描述
yizhi_train_cart=rpart(qg406~cfps_age+cfps_gender+cfps_latest_edu+pa301+qg17+qp605_s_1+qq501,
method="class",data=yizhi_train,control=rc)
#查看决策树模型
summary(yizhi_train_cart)
print(yizhi_train_cart)
rpart.plot(yizhi_train_cart, branch=1, branch.type=2, type=1, extra=102,
shadow.col="gray", box.col="yellow",
border.col="blue", split.col="red",
split.cex=1.2, main="剪枝前的决策树")
#绘制复杂度参数与交叉验证误差图
print(yizhi_train_cart$cptable)
plotcp(yizhi_train_cart)
#选择最小预测误差的决策树,并剪枝
opt<-which.min(yizhi_train_cart$cptable[,"xerror"])
opt
cp<-yizhi_train_cart$cptable[opt,"CP"]
cp
yizhi_train_cart_pruned<-prune(yizhi_train_cart,cp=cp)
#描述剪枝后的决策树
summary(yizhi_train_cart_pruned)
print(yizhi_train_cart_pruned)
#绘制决策树图
rpart.plot(yizhi_train_cart_pruned, branch=1, branch.type=2, type=1, extra=102,
shadow.col="gray", box.col="yellow",
border.col="blue", split.col="red",
split.cex=1.2, main="剪枝后的决策树")
#评估决策树-混淆矩阵
pre_train<-predict(yizhi_train_cart_pruned,yizhi_train[,-5],type="class")
tb1<-table(yizhi_train[,5],pre_train)
tb1
pre_test<-predict(yizhi_train_cart_pruned,yizhi_test[,-5],type="class")
tb2<-table(yizhi_test[,5],pre_test)
(sum(diag(tb1))/sum(tb1))
(sum(diag(tb2))/sum(tb2))
#提取剪枝决策树规则
print(yizhi_train_cart_pruned)
asRules(yizhi_train_cart_pruned)##设置工作空间
getwd()
setwd("/media/zty/aae84acb-4d27-47dc-b5a0-93a21d9f7cd9/zty/数据分析文件/262-结实-左手R右手Python数据挖掘机器学习/R语言案例/聚类分析")
#读取数据
Airline_data=read.csv("air_data1.csv",header=T, encoding = 'gbk')
#查看数据维度类型等信息
dim(Airline_data)
names(Airline_data)
str(Airline_data)
#转换数据类型:时间的字段为因子型数据,需要转换为日期格式。
Airline_data$FFP_DATE <- as.Date(Airline_data$FFP_DATE)
Airline_data$LOAD_TIME <- as.Date(Airline_data$LOAD_TIME)
Airline_data$LAST_FLIGHT_DATE <- as.Date(Airline_data$LAST_FLIGHT_DATE)
#查看数据内容等信息
summary(Airline_data)
#剔除异常数据并查看
attach(Airline_data)
Airline_data_clear <- Airline_data[-which(SUM_YR_1 ==0 | SUM_YR_2 ==0 |
is.na(SUM_YR_1)==1 | is.na(SUM_YR_2)==1 | avg_discount==0),]
detach(Airline_data)
summary(Airline_data_clear)
dim(Airline_data_clear)
#抽取模型所需因子
vars <- c("FFP_DATE","LOAD_TIME","FLIGHT_COUNT","SEG_KM_SUM","LAST_TO_END","avg_discount")
Airline_data_sub <- Airline_data_clear[,vars]
#查看数据集并数据处理
summary(Airline_data_sub)
str(Airline_data_sub)
#数据衍生
Airline_data_sub <- transform(Airline_data_sub, L = difftime(LOAD_TIME,FFP_DATE, units = "days"))
head(Airline_data_sub)
str(Airline_data_sub) #数据类型不符
#数据类型转换
Airline_data_sub$L <- as.numeric(Airline_data_sub$L)
str(Airline_data_sub)
#数据规范化-名称利于业务解读
Airline_data_sub <- transform(Airline_data_sub,
R = LAST_TO_END,
F = FLIGHT_COUNT,
M = SEG_KM_SUM,
C = avg_discount)
summary(Airline_data_sub)z_data <- data.frame(scale(Airline_data_sub[,c("R","F","M","C","L")]))
head(z_data)
write.csv(z_data, file = "/media/zty/aae84acb-4d27-47dc-b5a0-93a21d9f7cd9/zty/数据分析文件/262-结实-左手R右手Python数据挖掘机器学习/R语言案例/聚类分析/z_data.csv")
R语言聚类分析
##设置工作空间
getwd()
setwd("/media/zty/aae84acb-4d27-47dc-b5a0-93a21d9f7cd9/zty/数据分析文件/262-结实-左手R右手Python数据挖掘机器学习/R语言案例/聚类分析")
#读取并查看数据
clustering_data=read.csv("/media/zty/aae84acb-4d27-47dc-b5a0-93a21d9f7cd9/zty/数据分析文件/262-结实-左手R右手Python数据挖掘机器学习/R语言案例/聚类分析/z_data.csv",header=T)
summary(clustering_data)
dim(clustering_data)
head(clustering_data[,-1])
#聚类分析
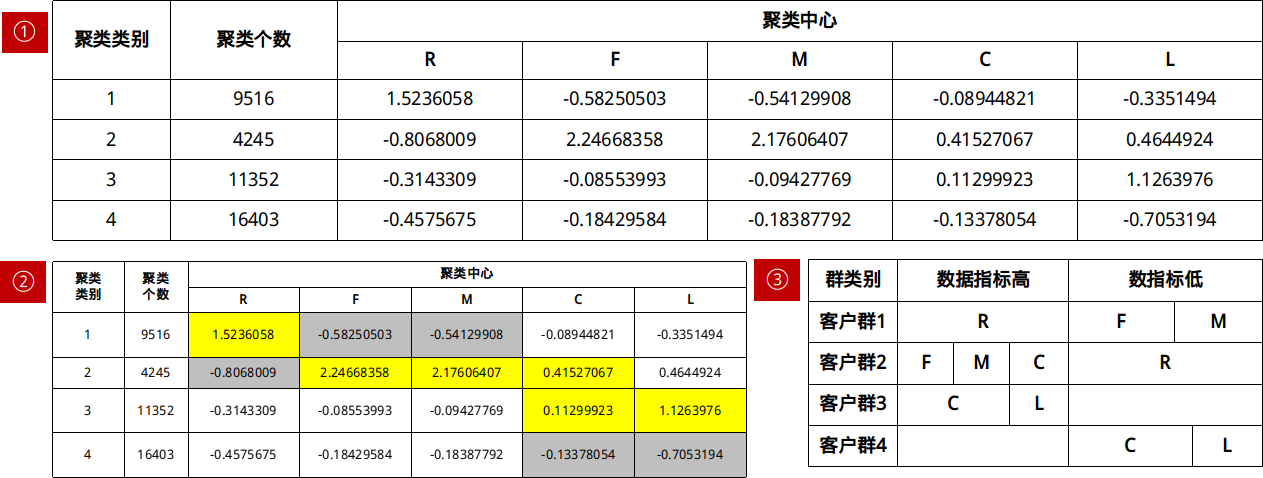
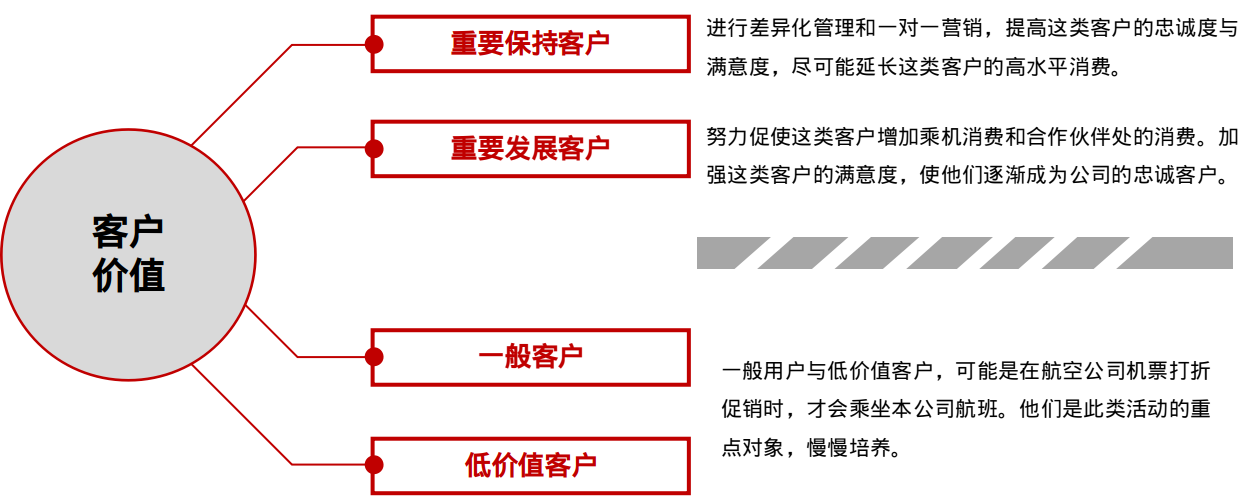
result = kmeans(clustering_data[,-1],center = 4)
#查看模型结果
result
result$centers
result$totss
result$withinss
result$tot.withinss
result$betweenss
result$size
result$iter
result$ifault
result$cluster
type = result$cluster
table(type)
#模型图形展示,生成聚类图
# install.packages("fpc")
library(fpc)
plotcluster(clustering_data[,-1], result$cluster)
#关联类别与属性
clustering_data_result <-cbind(clustering_data,type = result$cluster)
head(clustering_data_result)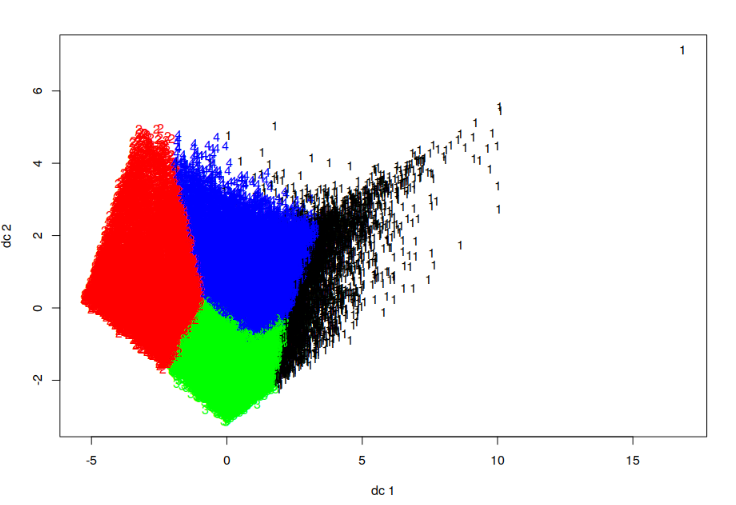








Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago