
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
核心pandas介绍
import numpy as np
import pandas as pd
df = pd.DataFrame({'key1':[4,5,3,np.nan,2],
'key2':[1,2,np.nan,4,5],
'key3':[1,2,3,'j','k']},
index = ['a','b','c','d','e'])
print(df)
print(df['key1'].dtype,df['key2'].dtype,df['key3'].dtype)
print('-----')
m1 = df.mean()
print(m1,type(m1))
print('单独统计一列:',df['key2'].mean())
print('-----')
# np.nan :空值
# .mean()计算均值
# 只统计数字列
# 可以通过索引单独统计一列
m2 = df.mean(axis=1)
print(m2)
print('-----')
# axis参数:默认为0,以列来计算,axis=1,以行来计算,这里就按照行来汇总了
m3 = df.mean(skipna=False)
print(m3)
print('-----')
# skipna参数:是否忽略NaN,默认True,如False,有NaN的列统计结果仍未NaN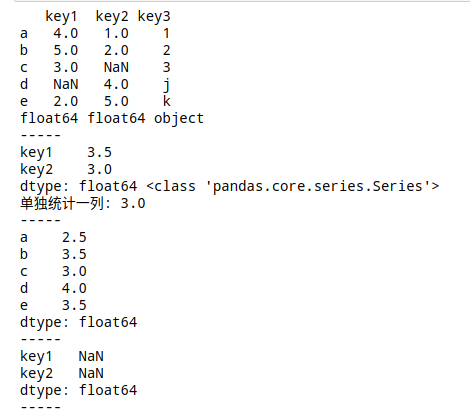
df = pd.DataFrame({'key1':np.arange(10),
'key2':np.random.rand(10)*10})
print(df)
print('-----')
print(df.count(),'→ count统计非Na值的数量\n')
print(df.min(),'→ min统计最小值\n',df['key2'].max(),'→ max统计最大值\n')
print(df.quantile(q=0.75),'→ quantile统计分位数,参数q确定位置\n')
print(df.sum(),'→ sum求和\n')
print(df.mean(),'→ mean求平均值\n')
print(df.median(),'→ median求算数中位数,50%分位数\n')
print(df.std(),'\n',df.var(),'→ std,var分别求标准差,方差\n')
print(df.skew(),'→ skew样本的偏度\n')
print(df.kurt(),'→ kurt样本的峰度\n')
df['key1_s'] = df['key1'].cumsum() df['key2_s'] = df['key2'].cumsum() print(df,'→ cumsum样本的累计和\n') df['key1_p'] = df['key1'].cumprod() df['key2_p'] = df['key2'].cumprod() print(df,'→ cumprod样本的累计积\n') print(df.cummax(),'\n',df.cummin(),'→ cummax,cummin分别求累计最大值,累计最小值\n') # 会填充key1,和key2的值

s = pd.Series(list('asdvasdcfgg'))
sq = s.unique()
print(s)
print(sq,type(sq))
print(pd.Series(sq))
# 得到一个唯一值数组
# 通过pd.Series重新变成新的Series
sq.sort()
print(sq)
# 重新排序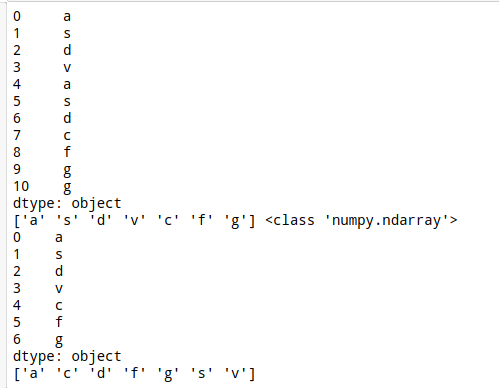
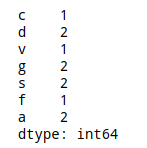
sc = s.value_counts(sort = False) # 也可以这样写:pd.value_counts(sc, sort = False) print(sc) # 得到一个新的Series,计算出不同值出现的频率 # sort参数:排序,默认为True
s = pd.Series(np.arange(10,15))
df = pd.DataFrame({'key1':list('asdcbvasd'),
'key2':np.arange(4,13)})
print(s)
print(df)
print('-----')
print(s.isin([5,14]))
print(df.isin(['a','bc','10',8]))
# 用[]表示
# 得到一个布尔值的Series或者Dataframe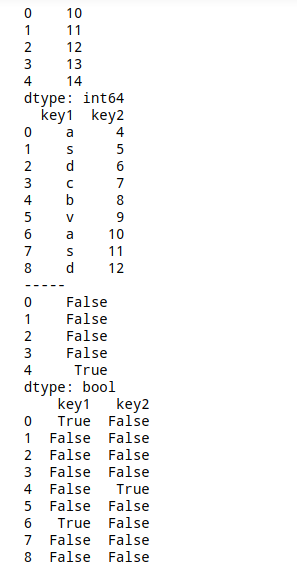
Pandas针对字符串配备的一套方法,使其易于对数组的每个元素进行操作
s = pd.Series(['A','b','C','bbhello','123',np.nan,'hj'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','123',np.nan]})
print(s)
print(df)
print('-----')
print(s.str.count('b'))
print(df['key2'].str.upper())
print('-----')
# 直接通过.str调用字符串方法
# 可以对Series、Dataframe使用
# 自动过滤NaN值
df.columns = df.columns.str.upper()
print(df)
# df.columns是一个Index对象,也可使用.str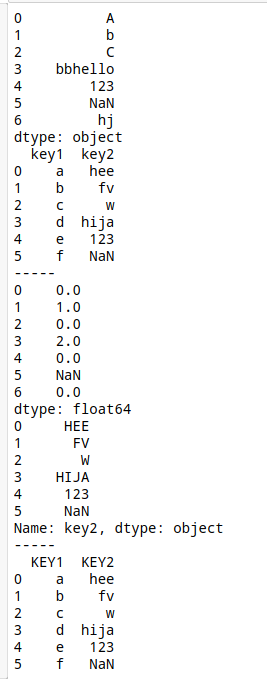
s = pd.Series(['A','b','bbhello','123',np.nan])
print(s.str.lower(),'→ lower小写\n')
print(s.str.upper(),'→ upper大写\n')
print(s.str.len(),'→ len字符长度\n')
print(s.str.startswith('b'),'→ 判断起始是否为a\n')
print(s.str.endswith('3'),'→ 判断结束是否为3\n')
s = pd.Series([' jack', 'jill ', ' jesse ', 'frank'])
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
print(s)
print(df)
print('-----')
print(s.str.strip()) # 去除字符串中的空格
print(s.str.lstrip()) # 去除字符串中的左空格
print(s.str.rstrip()) # 去除字符串中的右空格
df.columns = df.columns.str.strip()
print(df)
# 这里去掉了columns的前后空格,但没有去掉中间空格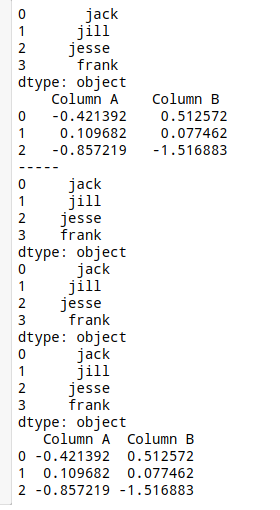
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
df.columns = df.columns.str.replace(' ','-')
print(df)
# 替换
df.columns = df.columns.str.replace('-','hehe',n=1)
print(df)
# n:替换个数
s = pd.Series(['a,b,c','1,2,3',['a,,,c'],np.nan])
print(s.str.split(','))
print('-----')
# 类似字符串的split
print(s.str.split(',')[0])
print('-----')
# 直接索引得到一个list
print(s.str.split(',').str[0])
print(s.str.split(',').str.get(1))
print('-----')
# 可以使用get或[]符号访问拆分列表中的元素
print(s.str.split(',', expand=True))
print(s.str.split(',', expand=True, n = 1))
print(s.str.rsplit(',', expand=True, n = 1))
print('-----')
# 可以使用expand可以轻松扩展此操作以返回DataFrame
# n参数限制分割数
# rsplit类似于split,反向工作,即从字符串的末尾到字符串的开头
df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']],
'key2':['a-b-c','1-2-3',[':-.- ']]})
print(df['key2'].str.split('-'))
# Dataframe使用split
s = pd.Series(['A','b','C','bbhello','123',np.nan,'hj'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','123',np.nan]})
print(s.str[0]) # 取第一个字符串
print(s.str[:2]) # 取前两个字符串
print(df['key2'].str[0])
# str之后和字符串本身索引方式相同
Pandas具有全功能的,高性能内存中连接操作,与SQL等关系数据库非常相似
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
# merge合并 → 类似excel的vlookup
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df3 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df4 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(pd.merge(df1, df2, on='key'))
print('------')
# left:第一个df
# right:第二个df
# on:参考键
print(pd.merge(df3, df4, on=['key1','key2']))
# 多个链接键
print(pd.merge(df3, df4,on=['key1','key2'], how = 'inner'))
print('------')
# inner:默认,取交集
print(pd.merge(df3, df4, on=['key1','key2'], how = 'outer'))
print('------')
# outer:取并集,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'left'))
print('------')
# left:按照df3为参考合并,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'right'))
# right:按照df4为参考合并,数据缺失范围NaN
df1 = pd.DataFrame({'lkey':list('bbacaab'),
'data1':range(7)})
df2 = pd.DataFrame({'rkey':list('abd'),
'date2':range(3)})
print(pd.merge(df1, df2, left_on='lkey', right_on='rkey'))
print('------')
# df1以‘lkey’为键,df2以‘rkey’为键
df1 = pd.DataFrame({'key':list('abcdfeg'),
'data1':range(7)})
df2 = pd.DataFrame({'date2':range(100,105)},
index = list('abcde'))
print(pd.merge(df1, df2, left_on='key', right_index=True))
# df1以‘key’为键,df2以index为键
# left_index:为True时,第一个df以index为键,默认False
# right_index:为True时,第二个df以index为键,默认False
# 所以left_on, right_on, left_index, right_index可以相互组合:
# left_on + right_on, left_on + right_index, left_index + right_on, left_index + right_index
df1 = pd.DataFrame({'key':list('bbacaab'),
'data1':[1,3,2,4,5,9,7]})
df2 = pd.DataFrame({'key':list('abd'),
'date2':[11,2,33]})
x1 = pd.merge(df1,df2, on = 'key', how = 'outer')
x2 = pd.merge(df1,df2, on = 'key', sort=True, how = 'outer')
print(x1)
print(x2)
print('------')
# sort:按照字典顺序通过 连接键 对结果DataFrame进行排序。默认为False,设置为False会大幅提高性能
print(x2.sort_values('data1'))
# 也可直接用Dataframe的排序方法:sort_values,sort_index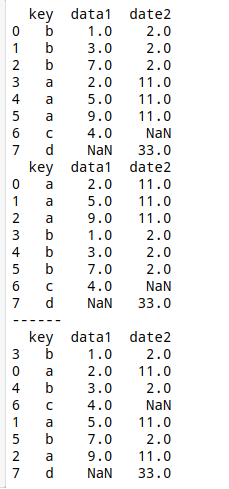
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
print(right)
print(left.join(right))
print(left.join(right, how='outer'))
print('-----')
# 等价于:pd.merge(left, right, left_index=True, right_index=True, how='outer')
df1 = pd.DataFrame({'key':list('bbacaab'),
'data1':[1,3,2,4,5,9,7]})
df2 = pd.DataFrame({'key':list('abd'),
'date2':[11,2,33]})
print(df1)
print(df2)
print(pd.merge(df1, df2, left_index=True, right_index=True, suffixes=('_1', '_2')))
print(df1.join(df2['date2']))
print('-----')
# suffixes=('_x', '_y')默认
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])
print(left)
print(right)
print(left.join(right, on = 'key'))
# 等价于pd.merge(left, right, left_on='key', right_index=True, how='left', sort=False);
# left的‘key’和right的index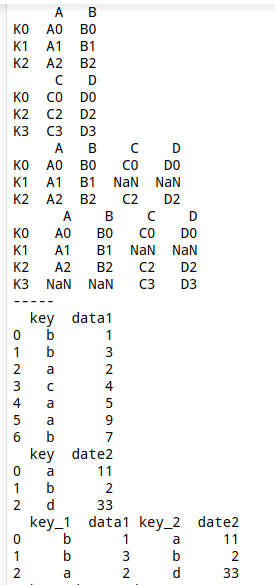


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago