
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Python数据分析实战——中国姓氏排行研究二
查看姓氏“普遍指数”,普遍指数=姓氏人口数量
查看姓氏“奔波指数”,奔波指数=姓氏人均迁徙距离。迁徙距离为户籍地所在地级市与现居住地所在地级市的距离。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
from bokeh.io import output_notebook
output_notebook()
# 导入notebook绘图模块
from bokeh.plotting import figure,show
from bokeh.models import ColumnDataSource
# 导入图表绘制、图标展示模块
# 导入ColumnDataSource模块'''
要求: ① 将数据按照“姓”做统计,找到数量最多的TOP20 ② 分别制作图表,查看姓氏TOP20的数量及占比 * 建议用bokeh出柱状图,并且为联动图表 ③ 查看“王”姓的全国分布 * 这里导出excel高版本文件,用powermap查看,绘制密度图 * 同时可以尝试用echarts绘制空间柱状图来查看 ④ 查看“姬”姓的全国分布 * 这里导出excel高版本文件,用powermap查看,绘制密度图 * 同时可以尝试用echarts绘制空间柱状图来查看 提示: ① bokeh中绘制联动图表时用gridplot ② powermap需要office2016的excel才会有,并且必须存储xlsx格式 ③ powermap中需要通过在“值”中设置“姓的计数”才能正确显示热力图 ④ powermap中可以通过“主题”来调节配色风格 / “平面地图”选项来调整球面可视化或者平面可视化 ⑤ echarts绘制图表之前,需要对数据按照“lng”(或者“lat”)汇总,得到同一个地点的该姓氏人数,然后绘图 ⑥ ecahrts通过设置以下参数来达到效果:视角远近、点柱大小
# 将数据按照“姓”做统计,找到数量最多的TOP10
name_count = df['姓'].value_counts()[:20]
result1_01 = pd.DataFrame({'count':name_count, 'count_pre':name_count/name_count.sum()})
# 筛选top20的姓氏,计数并计算占比
result1_01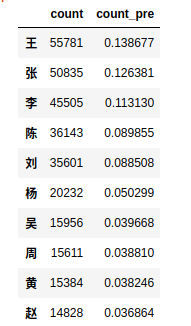
from bokeh.models import HoverTool
from bokeh.layouts import gridplot
# 导入模块
name_lst = result1_01.index.tolist()
source = ColumnDataSource(result1_01)
# 创建ColumnDataSource数据
hover1 = HoverTool(tooltips=[("姓氏计数", "@count")]) # 设置标签显示内容
result1 = figure(plot_width=800, plot_height=250,x_range = name_lst,
title="中国姓氏TOP20 - 计数" ,
tools=[hover1,'reset,xwheel_zoom,pan']) # 构建绘图空间
result1.vbar(x='index', top='count', source=source,width=0.9, alpha = 0.7,color = 'red')
result1.ygrid.grid_line_dash = [6, 4]
result1.xgrid.grid_line_dash = [6, 4]
# 柱状图1
hover2 = HoverTool(tooltips=[("姓氏占比", "@count_pre")]) # 设置标签显示内容
result2 = figure(plot_width=800, plot_height=250,x_range = result1.x_range,
title="中国姓氏TOP20 - 占比" ,
tools=[hover2,'reset,xwheel_zoom,pan'])
result2.vbar(x='index', top='count_pre', source=source,width=0.9, alpha = 0.7,color = 'green')
result2.ygrid.grid_line_dash = [6, 4]
result2.xgrid.grid_line_dash = [6, 4]
# 柱状图2
p = gridplot([[result1], [result2]])
# 组合图表
show(p)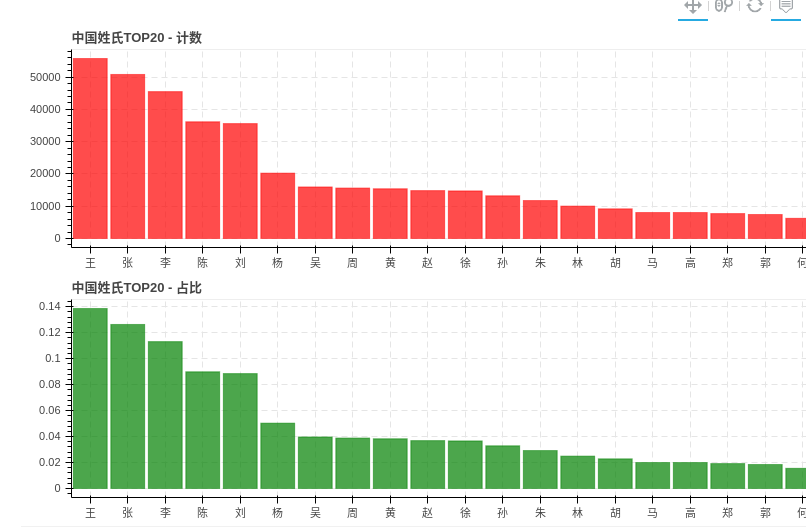
data_wang1 = df[df['姓'] == '王']
writer = pd.ExcelWriter('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究/wang1.xlsx')
data_wang1.to_excel(writer,'sheet1',index=False)
writer.save()
# 导出数据1
data_wang2 = data_wang1.groupby(['姓','户籍所在地_lng','户籍所在地_lat'])['户籍所在地_市'].count()
data_wang2 = data_wang2.reset_index()
writer = pd.ExcelWriter('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究/wang2.xlsx')
data_wang2.to_excel(writer,'sheet1',index=False)
writer.save()
# 导出数据2
print('导出完成!')
# 结论 → 老王们无处不在啊!
data_ji1 = df[df['姓'] == '姬']
writer = pd.ExcelWriter('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究/ji1.xlsx')
data_ji1.to_excel(writer,'sheet1',index=False)
writer.save()
# 导出数据1
data_ji2 = data_ji1.groupby(['姓','户籍所在地_lng','户籍所在地_lat'])['户籍所在地_市'].count()
data_ji2 = data_ji2.reset_index()
writer = pd.ExcelWriter('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究/ji2.xlsx')
data_ji2.to_excel(writer,'sheet1',index=False)
writer.save()
# 导出数据2
print('导出完成!')
# 结论 → “姬”传说是黄帝之姓、周朝国姓,并且是10大姓中7个姓的起源
# 千年过去,姬姓后嗣多已改为他姓,开枝散叶。而还保留着这个古老姓氏的人口,也仍然栖息在古老中华文明的发源地——河南。
'''
要求:
① 根据识别的工作地,通过Geocoding查询到对应坐标
② 选择一个姓氏,计算并查看其姓氏的奔波指数,并计算该姓氏的人均通勤距离
* 在python中筛选数据之后,qgis内做空间分析
③ 按照起点和终点做计数,汇总同一个迁徙路径的数据
④ 通过echart制作通勤OD图
* 可以将生成的line文件导出geojson,用空间线性轨迹图来表示
* 这里线的valye为该迁徙路径的汇总计数
提示:
① 可以筛选一些好玩的姓氏:汤、朴、廉、何、叶、冉等等
② 需要对数据的工作地进行筛选,其中“工作地_市”、“工作地_区县”未识别的数据删除掉
③ 导出数据时,尽量columns名用全英文,避免qgis中出现乱码
④ 计算人均通勤距离的时候,需要删除掉户籍地与工作地相同的人(未迁移的人)
⑤ 在官网metrodata.cn的小工具中找到geocoding
⑥ qgis中需要安装插件“LinePlotter”来转线,并在qgis中计算平均通勤距离(需要投影,投影经度带可选48)
⑦ shapefile转geojson时,注意shapefile文件要投影回wgs84地理坐标系
data_tang = df[['姓','户籍所在地_lng','户籍所在地_lat','工作地_市','工作地_区县']][df['姓'] == '汤']
data_tang = data_tang[data_tang['工作地_市'] != '未识别']
data_tang = data_tang[data_tang['工作地_区县'] != '未识别']
data_tang.columns = ['familyname','birth_lng','birth_lat','work_city','work_district']
# 筛选并清洗数据
writer = pd.ExcelWriter('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究/tang.xlsx')
data_tang.to_excel(writer,'sheet1',index=False)
writer.save()
# 导出数据
print('数据条数为%i条' % len(data_tang))
data_tang.head(10)
数据文件链接:链接: https://pan.baidu.com/s/1DwgbgCjENL5d3M2U0pHEmA 密码: t6b2


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago