
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Python数据分析实战——中国姓氏排行研究一
中国姓氏排行研究
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
from bokeh.io import output_notebook
output_notebook()
# 导入notebook绘图模块
from bokeh.plotting import figure,show
from bokeh.models import ColumnDataSource
# 导入图表绘制、图标展示模块
# 导入ColumnDataSource模块

'''
1、数据清洗、整合
要求:
① 将“data01”、“data02”分别读取,并且合并成一个数据
② 结合“户籍地城市编号”及“中国城市代码对照表”数据,将城市经纬度连接进数据中
③ 分别提取“工作地”中的省、市
提示:
① 可以先读取“data01”、“data02”,然后用pd.concat()来连接数据
② 新建字段“工作地-省”,“工作地-市”,“工作地-区县”,如果数据中“工作地”字段无法提取省和市,则用“未识别”填充单元格
* 通过查看识别后的单元格,如果字数超过5则为“未识别”
'''
# 查看数据,数据清洗
import os
os.chdir('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习05_中国姓氏排行研究')
# 创建工作路径
df01 = pd.read_csv('data01.csv',encoding = 'utf-8')
df02 = pd.read_csv('data02.csv',encoding = 'utf-8')
df_city = pd.read_excel('中国行政代码对照表.xlsx')
# 读取数据
df = pd.concat([df01,df02])
df_city['行政编码'] = df_city['行政编码'].apply(str)
df = pd.merge(df,df_city,left_on='户籍地城市编号',right_on = '行政编码')
df['工作地'] = df['工作地'].str[:15] # 只提取工作地前15个字符即可
del df['行政编码']
del df['户籍地城市编号']
# 合并数据,添加经纬度字段
# 删除无用字段
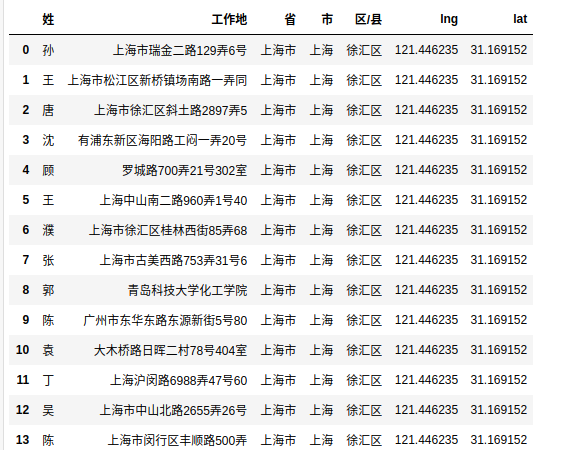
print('读取数据共%i条' % len(df))
df.head(20)
# 分别提取“工作地”中的省、市、区县
# 新建字段“工作地-省”,“工作地-市”,“工作地-区县”,如果数据中“工作地”字段无法提取省和市,则用“未识别”填充单元格
# *通过查看识别后的单元格,如果字数超过5则为“未识别”
df['工作地_省'] = df['工作地'].str.split('省').str[0]
# 识别工作地-省
df['工作地_市'] = df['工作地'].str.split('省').str[1].str.split('市').str[0]
df['工作地_市'][df['工作地_省'].str.len() > 5] = df['工作地_省'].str.split('市').str[0]
# 识别工作地-市
# 在未识别出省的数据中,可能会有市的信息
df['工作地_区县'] = ''
df['工作地_区县'][(df['工作地_市'].str.len() < 5)&(df['工作地'].str.contains('区'))] = df['工作地'].str.split('市').str[1].str.split('区').str[0] + '区'
df['工作地_区县'][(df['工作地_市'].str.len() > 5)&(df['工作地'].str.contains('区'))] = df['工作地'].str.split('区').str[0] + '区'
df['工作地_区县'][(df['工作地_市'].str.len() < 5)&(df['工作地'].str.contains('县'))] = df['工作地'].str.split('市').str[1].str.split('县').str[0] + '县'
df['工作地_区县'][(df['工作地_市'].str.len() > 5)&(df['工作地'].str.contains('县'))] = df['工作地'].str.split('县').str[0] + '县'
# 识别工作地-区县
df['工作地_省'][df['工作地_省'].str.len() > 5] = '未识别'
df['工作地_市'][df['工作地_市'].str.len() > 5] = '未识别'
df['工作地_区县'][(df['工作地_区县'].str.len() > 5) | (df['工作地_区县'].str.len() < 2)] = '未识别'
# 整理未识别单元格
df.columns = ['姓','工作地','户籍所在地_省','户籍所在地_市','户籍所在地_区县','户籍所在地_lng','户籍所在地_lat',
'工作地_省','工作地_市','工作地_区县']
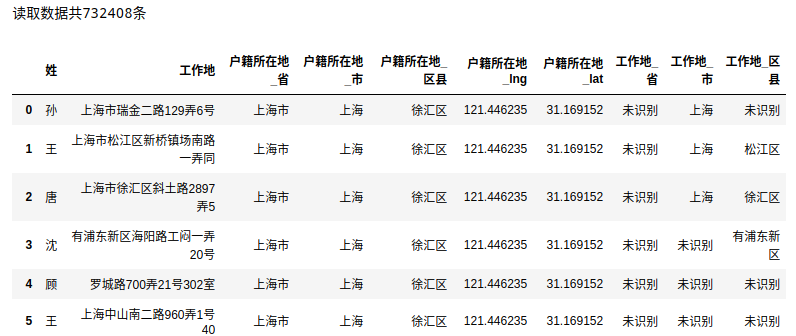
print('读取数据共%i条' % len(df))
# 数据整理
df.head(20)


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago