
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Python数据分析分析电商打折套路
'''
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
from bokeh.io import output_notebook
output_notebook()
# 导入notebook绘图模块
from bokeh.plotting import figure,show
from bokeh.models import ColumnDataSource
# 导入图表绘制、图标展示模块
# 导入ColumnDataSource模块
'''要求:
① 计算得到:商品总数、品牌总数
② 双十一当天在售的商品占比情况(思考:是不是只有双十一当天在售的商品是“参与双十一活动的商品?”)
③ 未参与双十一当天活动的商品,在双十一之后的去向如何?
④ 真正参与双十一活动的品牌有哪些?其各个品牌参与双十一活动的商品数量分布是怎样的?
* 用bokeh绘制柱状图表示
提示:
① 数据的“id”字段为商品的实际唯一标识,“title”字段则为商品在网页上显示的名称
* 仔细看数据可以发现,同一个id的title不一定一样(双十一前后)
② 数据的“店名”字段为品牌的唯一标识
③ 按照商品销售节奏分类,我们可以将商品分为7类
A. 11.11前后及当天都在售 → 一直在售
B. 11.11之后停止销售 → 双十一后停止销售
C. 11.11开始销售并当天不停止 → 双十一当天上架并持续在售
D. 11.11开始销售且当天停止 → 仅双十一当天有售
E. 11.5 - 11.10 → 双十一前停止销售
F. 仅11.11当天停止销售 → 仅双十一当天停止销售
G. 11.12开始销售 → 双十一后上架
④ 未参与双十一当天活动的商品,可能有四种情况:
con1 → 暂时下架(F)
con2 → 重新上架(E中部分数据,数据中同一个id可能有不同title,“换个马甲重新上架”),字符串查找特定字符 dataframe.str.contains('预售')
con3 → 预售(E中部分数据,预售商品的title中包含“预售”二字)
con4 → 彻底下架(E中部分数据),可忽略
⑤ 真正参加活动的商品 = 双十一当天在售的商品 + 预售商品 (可以尝试结果去重)
通过上述几个指标计算,研究出哪些是真正参与双十一活动的品牌,且其商品数量是多少
'''
# 查看数据, 计算商品总数、品牌总数
import os
os.chdir('/home/zty/Documents/python/Python进阶数据分析及可视化/实战/练习04_电商打折套路解析/')
# 创建工作路径
df = pd.read_excel('双十一淘宝美妆数据.xlsx',sheet_name=0,header=0,index_col=0)
df_length = len(df)
df_columns = df.columns.tolist()
df.fillna(0,inplace = True) # 填充缺失值
df['date'] = df.index.day # 提取销售日期
print('数据量为%i条' % len(df))
print('数据时间周期为:\n', df.index.unique())
df.head()
# 双十一当天在售的商品占比情况
# 按照商品销售节奏分类,我们可以将商品分为7类
# A. 11.11前后及当天都在售 → 一直在售
# B. 11.11之后停止销售 → 双十一后停止销售
# C. 11.11开始销售并当天不停止 → 双十一当天上架并持续在售
# D. 11.11开始销售且当天停止 → 仅双十一当天有售
# E. 11.5 - 11.10 → 双十一前停止销售
# F. 仅11.11当天停止销售 → 仅双十一当天停止销售
# G. 11.12开始销售 → 双十一后上架
data1 = df[['id','title','店名','date']]
#print(data1.head())
# 筛选数据
d1 = data1[['id','date']].groupby(by = 'id').agg(['min','max'])['date']
# 统计不同商品的销售开始日期、截止日期
id_11 = data1[data1['date']==11]['id'].unique()
d2 = pd.DataFrame({'id':id_11,'双十一当天是否售卖':True})
# 筛选双十一当天售卖的商品id
id_date = pd.merge(d1,d2,left_index=True,right_on='id',how = 'left')
id_date['双十一当天是否售卖'][id_date['双十一当天是否售卖']!=True] = False
#print(id_date.head())
# 合并数据
m = len(data1['id'].unique())
m_11 = len(id_11)
m_11_pre = m_11/m
print('商品总数为%i个\n-------' % m)
print('双十一当天参与活动的商品总数为%i个,占比为%.2f%%\n-------' % (m_11,m_11_pre*100))
print('品牌总数为%i个\n' % len(data1['店名'].unique()),data1['店名'].unique())
# 统计
id_date['type'] = '待分类'
id_date['type'][(id_date['min'] <11)&(id_date['max']>11)] = 'A' # A类:11.11前后及当天都在售 → 一直在售
id_date['type'][(id_date['min'] <11)&(id_date['max']==11)] = 'B' # B类:11.11之后停止销售 → 双十一后停止销售
id_date['type'][(id_date['min'] ==11)&(id_date['max']>11)] = 'C' # C类:11.11开始销售并当天不停止 → 双十一当天上架并持续在售
id_date['type'][(id_date['min'] ==11)&(id_date['max']==11)] = 'D' # D类:11.11开始销售且当天停止 → 仅双十一当天有售
id_date['type'][id_date['双十一当天是否售卖']== False] = 'F' # F类:仅11.11当天停止销售 → 仅双十一当天停止销售
id_date['type'][id_date['max']<11] = 'E' # E类:11.5 - 11.10 → 双十一前停止销售
id_date['type'][id_date['min'] >11] = 'G' # G类:11.11之后开始销售 → 双十一后上架
# 商品销售节奏分类
result1 = id_date['type'].value_counts()
result1 = result1.loc[['A','C','B','D','E','F','G']] # 调整顺序
# 计算不同类别的商品数量
from bokeh.palettes import brewer
colori = brewer['YlGn'][7]
# 设置调色盘
plt.axis('equal') # 保证长宽相等
plt.pie(result1,labels = result1.index, autopct='%.2f%%',pctdistance=0.8,labeldistance =1.1,
startangle=90, radius=1.5,counterclock=False, colors = colori)
# 绘制饼图
result1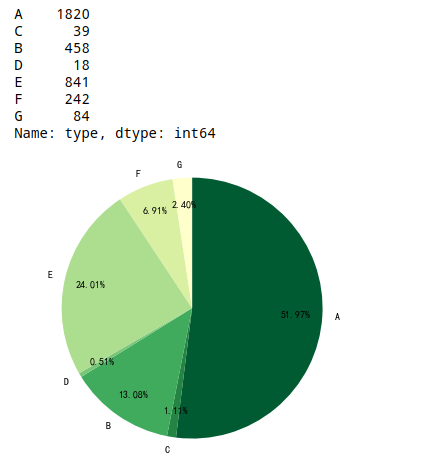
# 未参与双十一当天活动的商品,在双十一之后的去向如何?
# con1 → 暂时下架(F)
# con2 → 重新上架(E中部分数据,数据中同一个id可能有不同title,“换个马甲重新上架”)
# con3 → 预售(E中部分数据,预售商品的title中包含“预售”二字),字符串查找特定字符 dataframe.str.contains('预售')
# con4 → 彻底下架(E中部分数据),可忽略
id_not11 = id_date[id_date['双十一当天是否售卖']==False] # 筛选出双十一当天没参加活动的产品id
print('双十一当天没参加活动的商品总数为%i个,占比为%.2f%%\n-------' % (len(id_not11),len(id_not11)/m*100))
print('双十一当天没参加活动的商品销售节奏类别为:\n',id_not11['type'].value_counts().index.tolist())
print('------')
# 找到未参与双十一当天活动的商品id
df_not11 = id_not11[['id','type']]
data_not11 = pd.merge(df_not11,df,on = 'id', how = 'left')
# 筛选出未参与双十一当天活动商品id对应的原始数据
id_con1 = id_date['id'][id_date['type'] == 'F'].values
# 筛选出con1的商品id
# con1 → 暂时下架(F)
data_con2 = data_not11[['id','title','date']].groupby(by = ['id','title']).count() # 按照id和title分组(找到id和title一对多的情况)
title_count = data_con2.reset_index()['id'].value_counts() # 计算id出现的次数,如果出现次数大于1,则说明该商品是更改了title的
id_con2 = title_count[title_count>1].index
# 筛选出con2的商品id
# con2 → 重新上架(E中部分数据,数据中同一个id可能有不同title,“换个马甲重新上架”)
data_con3 = data_not11[data_not11['title'].str.contains('预售')] # 筛选出title中含有“预售”二字的数据
id_con3 = data_con3['id'].value_counts().index
# 筛选出con3的商品id
# con3 → 预售(E中部分数据,预售商品的title中包含“预售”二字)
print("未参与双十一当天活动的商品中:\n暂时下架商品的数量为%i个,重新上架商品的数据量为%i个,预售商品的数据量为%i个"
% (len(id_con1), len(id_con2), len(id_con3)))
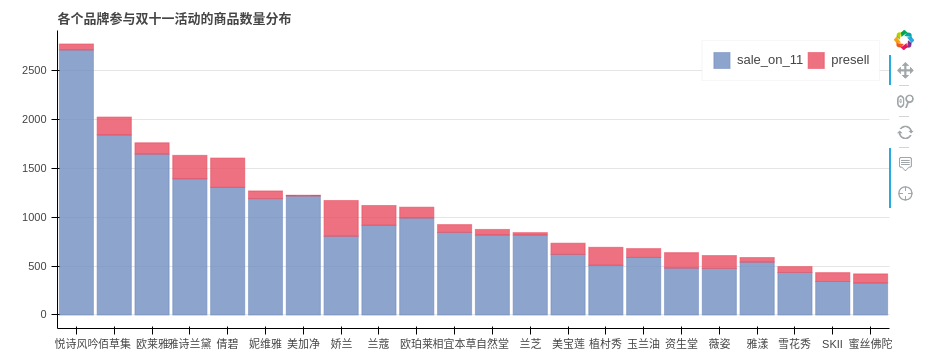
# 真正参与双十一活动的品牌有哪些?其各个品牌参与双十一活动的商品数量分布是怎样的?
# 真正参加活动的商品 = 双十一当天在售的商品 + 预售商品 (相加后再去重,去掉预售且当天在售的商品)
data_11sale = id_11
#print('双十一当天在售的商品的数量为%i个\n' % len(data_11sale),data_11sale)
#print('--------')
# 得到“双十一当天在售的商品”id及数量
id_11sale_final = np.hstack((data_11sale,id_con3))
result2_id = pd.DataFrame({'id':id_11sale_final})
print('商品总数为%i个' % m)
print('真正参加活动的商品商品总数为%i个,占比为%.2f%%\n-------' % (len(result2_id),len(result2_id)/m*100))
#result2['id'].duplicated()
# 得到真正参与双十一活动的商品id
x1 = pd.DataFrame({'id':id_11})
x1_df = pd.merge(x1,df,on = 'id', how = 'left') # 筛选出真正参与活动中 当天在售的商品id对应源数据
brand_11sale = x1_df.groupby('店名')['id'].count()
# 得到不同品牌的当天参与活动商品的数量
x2 = pd.DataFrame({'id':id_con3})
x2_df = pd.merge(x2,df,on = 'id', how = 'left') # 筛选出真正参与活动中 当天在售的商品id对应源数据
brand_ys = x2_df.groupby('店名')['id'].count()
# 得到不同品牌的预售商品的数量
result2_data = pd.DataFrame({'当天参与活动商品数量':brand_11sale,
'预售商品数量':brand_ys})
result2_data['参与双十一活动商品总数'] = result2_data['当天参与活动商品数量'] + result2_data['预售商品数量']
result2_data.sort_values(by = '参与双十一活动商品总数',inplace = True,ascending = False)
result2_data
from bokeh.models import HoverTool
from bokeh.core.properties import value
# 导入相关模块
lst_brand = result2_data.index.tolist()
lst_type = result2_data.columns.tolist()[:2]
colors = ["#718dbf" ,"#e84d60"]
# 设置好参数
result2_data.index.name = 'brand'
result2_data.columns = ['sale_on_11','presell','sum']
# 修改数据index和columns名字为英文
source = ColumnDataSource(data=result2_data)
# 创建数据
hover = HoverTool(tooltips=[("品牌", "@brand"),
("双十一当天参与活动的商品数量", "@sale_on_11"),
("预售商品数量", "@presell"),
("参与双十一活动商品总数", "@sum")
]) # 设置标签显示内容
p = figure(x_range=lst_brand, plot_width=900, plot_height=350, title="各个品牌参与双十一活动的商品数量分布",
tools=[hover,'reset,xwheel_zoom,pan,crosshair'])
# 构建绘图空间
p.vbar_stack(lst_type, # 设置堆叠值,这里source中包含了不同年份的值,years变量用于识别不同堆叠层
x='brand', # 设置x坐标
source=source,
width=0.9, color=colors, alpha = 0.8,legend=[value(x) for x in lst_type],
muted_color='black', muted_alpha=0.2
)
# 绘制堆叠图
p.xgrid.grid_line_color = None
p.axis.minor_tick_line_color = None
p.outline_line_color = None
p.legend.location = "top_right"
p.legend.orientation = "horizontal"
p.legend.click_policy="mute"
# 设置其他参数show(p)


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago