
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
python采集信息+Python预处理+tableau绘制可视化大屏
* 制作完成的效果:



注:这个图绘制的右上角违和感较高,所以各位小伙伴绘制时要注意不要使用这种大块的图形,绘制一些可以设置背景色为透明的哪一种。
最后一张图的话设计的是1920*1080的大小,太大了,所以录制的时候并没有完全录制上。
* 现在制作可视化大屏的方法我遇见的主要有两种:一是使用Python flask+ajax+ECharts绘图库,二就是使用tableau。当然使用power bi和fine bi的话应该也是可以绘制的,感兴趣的小伙伴可以尝试一下。
第一种方法的话:在b站上面有学习链接:学习链接。
主要思路是:
1.利用Python获取到数据,如从数据库、csv、excel中获取。
2.利用ajax把前端页面和后台flask数据进行交互。
3.把后端获取的数据传给前端,在前端利用echarts绘制要使用的图形。
第二种方法较简单,直接使用可视化绘图软件就可以绘制。下面介绍一下使用tableau绘制大屏。
绘制思路:
*1.获取数据集,对数据集进行预处理,处理成我们想要的赶紧数据。
* 2.使用tableau绘制出来每一个子图。
* 3.使用tableau把子图组合绘制出交互图。
下面是在b站中使用该方法绘制出来的图形成品,都挺高大上的,对可视化大屏,Python感兴趣的小伙伴可以学习一下。


这一个步骤我是使用Python爬取到的数据,并使用Python进行的预处理。
获取数据的代码:
import requests
import pandas as pd
from pprint import pprint
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
for i in range(1,1501):
print("正在爬取第" + str(i) + "页的数据")
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,"
url_end = ".html?"
url = url_pre + str(i) + url_end
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
web = requests.get(url, headers=headers)
web.encoding = "gbk"
dom = etree.HTML(web.text)
# 1、岗位名称
job_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@title')
# 2、公司名称
company_name = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t2"]/a[@target="_blank"]/@title')
# 3、工作地点
address = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t3"]/text()')
# 4、工资
salary_mid = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t4"]')
salary = [i.text for i in salary_mid]
# 5、发布日期
release_time = dom.xpath('//div[@class="dw_table"]/div[@class="el"]/span[@class="t5"]/text()')
# 6、获取二级网址url
deep_url = dom.xpath('//div[@class="dw_table"]/div[@class="el"]//p/span/a[@target="_blank"]/@href')
RandomAll = []
JobDescribe = []
CompanyType = []
CompanySize = []
Industry = []
for i in range(len(deep_url)):
web_test = requests.get(deep_url[i], headers=headers)
web_test.encoding = "gbk"
dom_test = etree.HTML(web_test.text)
# 7、爬取经验、学历信息,先合在一个字段里面,以后再做数据清洗。命名为random_all
random_all = dom_test.xpath('//div[@class="tHeader tHjob"]//div[@class="cn"]/p[@class="msg ltype"]/text()')
# 8、岗位描述性息
job_describe = dom_test.xpath('//div[@class="tBorderTop_box"]//div[@class="bmsg job_msg inbox"]/p/text()')
# 9、公司类型
company_type = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[1]/@title')
# 10、公司规模(人数)
company_size = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[2]/@title')
# 11、所属行业(公司)
industry = dom_test.xpath('//div[@class="tCompany_sidebar"]//div[@class="com_tag"]/p[3]/@title')
# 将上述信息保存到各自的列表中
RandomAll.append(random_all)
JobDescribe.append(job_describe)
CompanyType.append(company_type)
CompanySize.append(company_size)
Industry.append(industry)
# 为了反爬,设置睡眠时间
time.sleep(1)
# 由于我们需要爬取很多页,为了防止最后一次性保存所有数据出现的错误,因此,我们每获取一夜的数据,就进行一次数据存取。
df = pd.DataFrame()
df["岗位名称"] = job_name
df["公司名称"] = company_name
df["工作地点"] = address
df["工资"] = salary
df["发布日期"] = release_time
df["经验、学历"] = RandomAll
df["公司类型"] = CompanyType
df["公司规模"] = CompanySize
df["所属行业"] = Industry
df["岗位描述"] = JobDescribe
# 这里在写出过程中,有可能会写入失败,为了解决这个问题,我们使用异常处理。
try:
df.to_csv("job_info.csv", mode="a+", header=None, index=None, encoding="gbk")
except:
print("当页数据写入失败")
time.sleep(1)部分预处理:
对公司名和发布的岗位数据去重:
# 去重之前的记录数
print("去重之前的记录数",df.shape)
# 记录去重
df.drop_duplicates(subset=["公司名","岗位名"],inplace=True)
# 去重之后的记录数
print("去重之后的记录数",df.shape)对岗位名的英文大小写处理成一致:
df["岗位名"].value_counts() df["岗位名"] = df["岗位名"].apply(lambda x:x.lower())
对相似的岗位进行统一化处理,如:数据专员,数据统计:
job_list = ['数据分析', "数据统计","数据专员",'数据挖掘', '算法',
'大数据','开发工程师', '运营', '软件工程', '前端开发',
'深度学习', 'ai', '数据库', '数据库', '数据产品',
'客服', 'java', '.net', 'andrio', '人工智能', 'c++',
'数据管理',"测试","运维"]
job_list = np.array(job_list)
def rename(x=None,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info["岗位名"] = job_info["岗位名"].apply(rename)
job_info["岗位名"].value_counts()
# 数据统计、数据专员、数据分析统一归为数据分析
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据专员","数据分析",x))
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据统计","数据分析",x))对工资水平进行处理,把千、万化为数字:
job_info["工资"].str[-1].value_counts()
job_info["工资"].str[-3].value_counts()
index1 = job_info["工资"].str[-1].isin(["年","月"])
index2 = job_info["工资"].str[-3].isin(["万","千"])
job_info = job_info[index1 & index2]
def get_money_max_min(x):
try:
if x[-3] == "万":
z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)]
elif x[-3] == "千":
z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)]
if x[-1] == "年":
z = [i/12 for i in z]
return z
except:
return x
salary = job_info["工资"].apply(get_money_max_min)
job_info["最低工资"] = salary.str[0]
job_info["最高工资"] = salary.str[1]
job_info["工资水平"] = job_info[["最低工资","最高工资"]].mean(axis=1)因为数据采集时间较长,代码的采集效率并不高,感兴趣的小伙伴可以添加线程来增加采集效率。采集完之后的数据链接: https://pan.baidu.com/s/19asuZsR2vzyf1Ndy3wkhUg 密码: rdre
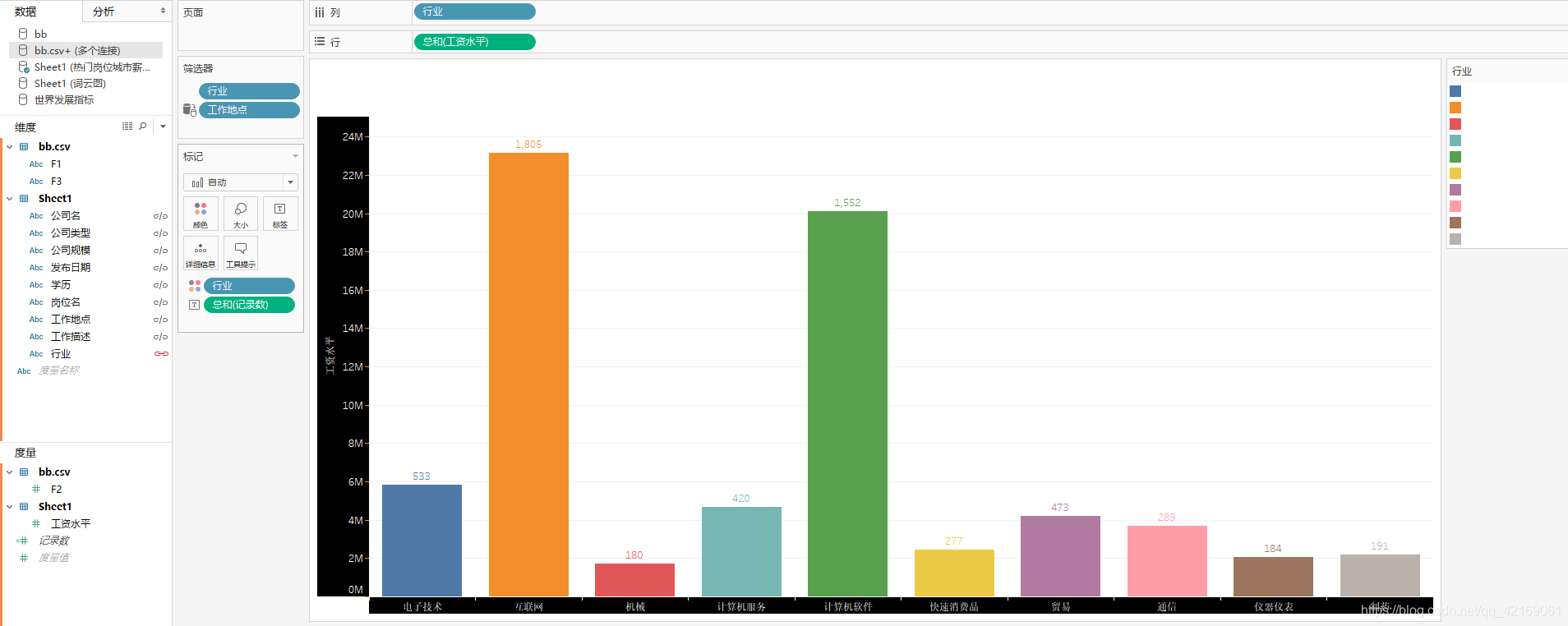
注:这个图吧,看着有点不那么友好是因为在绘制交互图时调节了阴影,颜色等属性。


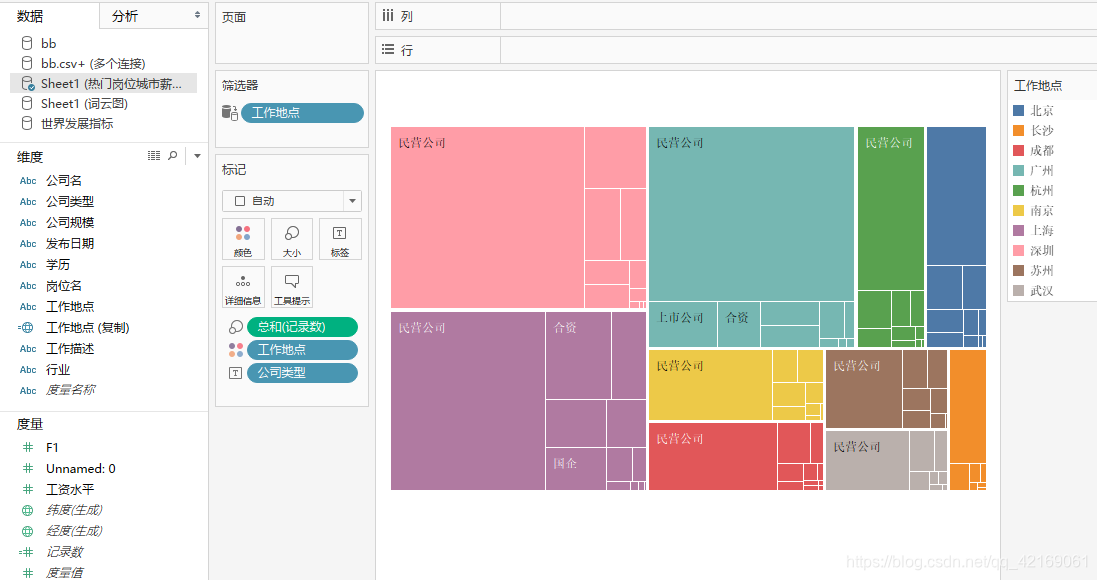

注:这个图没有图标等属性的原因是:大屏背景为黑色,这里都设置为了白色,底色为无。
1.确定要绘制的仪表盘大小。后面绘制交互图时中要选择一张背景图片,必须和这个大小相同。

2.然后搜索一张喜欢的图片但是必须是这个大小的图形,选择平铺----双击图像----选择背景图。

选择完图形之后的结果图为:

3.选择浮动,把绘制好的图形拖动到仪表盘中。这个图看着违和感较高,需要调节颜色等属性。*<center>

4.下面就是要调节的具体细节,1.设置背景阴影为无,2.设置标题颜色为白色,3.设置轴颜色,刻度颜色为白色。*<center>


5.删除每一个图的筛选器只留出一个公共的筛选器,并把该筛选器应用到使用相关数据源的所有项。*<center>

6.最后调节适用于整个视图,全屏就可以看展示效果了。*<center>
最后:图的绘制比较自由,每一个子图都可以看自己想象力和创造力来绘制,背景图看个人喜好可以选择不同的图形。为了最后绘制的图形好看,一、不要使用块状的图形或不能设置背景色为无的图形。二、配色,色调要一致,绘制成统一的颜色将会有更好的效果。


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago