
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
第 3 章 11 条数据化运营不得不知道的数据预处理经验三
所谓的不均衡指的是不同类别的样本量差异非常大。样本类别分布不均衡主要出现在分类相关的建模问题上。样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数据分布不均衡两种。
·大数据分布不均衡;这种情况下整体数据规模大,只是其中的小样本类的占比较少。但是从每个特征的分布来看,小样本也覆盖了大部分或全部的特征。例如拥有 1000 万条记录的数据集中,其中占比 50 万条的少数分类样本便于属于这种情况。
·小数据分布不均衡;这种情况下整体数据规模小,并且占据少量样本比例的分类数量也少,这会导致特征分布的严重不平衡。例如拥有1000 条数据样本的数据集中,其中占有 10 条样本的分类,其特征无论如何拟合也无法实现完整特征值的覆盖,此时属于严重的数据样本分布不均衡。样本分布不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律;即使得到分类模型,也容易产生过度依赖于有限的数据样本而导致过拟合的问题,当模型应用到新的数据上时,模型的准确性和健壮性将很差。样本分布不均衡主要在于不同类别间的样本比例差异。如果不同分类间的样本量差异达到超过 10 倍就需要引起警觉并考虑处理该问题,超过 20 倍就一定要解决了。
·异常检测场景 。大多数企业中的异常个案都是少量的,比如恶意刷单、黄牛订单、信用卡欺诈、电力窃电、设备故障等,这些数据样本所占的比例通常是整体样本中很少的一部分,以信用卡欺诈为例,刷实体信用卡的欺诈比例一般都在 0.1% 以内。
·客户流失场景 。大型企业的流失客户相对于整体客户而言通常是少量的,尤其对于具有垄断地位的行业巨擘,例如电信、石油、网络运营商等更是如此。
·罕见事件的分析 。罕见事件与异常检测类似,都属于发生个案较少,不同点在于异常检测通常都有预先定义好的规则和逻辑,并且大多数异常事件都会对企业运营造成负面影响,因此针对异常事件的检测和预防非常重要;罕见事件则无法预判,并且也没有明显的积极或消极影响倾向。例如由于某网络大 V无意中转发了企业的一条趣味广告导致用户流量明显提升便属于此类。
·发生频率低的事件 。这种事件是预期或计划性事件,但是发生频率非常低。例如每年 1次的双 11 盛会一般都会产生较高的销售额,但放到全年来看这一天的销售额占比很可能只有 1% 不到,尤其对于很少参与活动的公司而言,这种情况更加明显。这就属于典型的低频事件。通过过抽样和欠抽样解决样本不均衡抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠抽样两种。
1)过抽样:又称上采样或( over-sampling ),其通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录。这种方法的缺点是,如果样本特征少则可能导致过拟合的问题。经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如 SMOTE 算法。
2)欠抽样:又称下采样( under-sampling ),其通过减少分类中多数类样本的数量来实现样本均衡,最直接的方法是随机去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。总体上,过抽样和欠抽样更适合大数据分布不均衡的情况,尤其是过抽样方法,应用极为广泛。通过正负样本的惩罚权重解决样本不均衡通过正负样本的惩罚权重解决样本不均衡的问题的思想:在算法实现过程中,对于分类中不同样本数量的类别分别赋予不同的权重(一般思路分类中的小样本量类别权重高,大样本量类别权重低),然后进行计算和建模。使用这种方法时需要对样本本身做额外处理,只需在算法模型的参数中进行相应设置即可。很多模型和算法中都有基于类别参数的调整设置,以 scikit-learn 中的 SVM 为例,通过在 class_weight:{dict ,'balanced'}中针对不同类别来手动指定权重。如果使用其默认的方法 balanced ,那么SVM 会将权重设置为与不同类别样本数量呈反比的权重来进行自动均衡处理,计算公式为:n_samples / (n_classes * np.bincount(y))如果算法本身支持,这种思路是更加简单且高效的方法。
组合 /集成方法指的是在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果。例如,数据集中的正、负例的样本分别为 100 和10000 条,比例为1:100 。此时可以将负例样本(类别中的大量样本集)随机分为 100 份(当然也可以分更多),每份 100 条数据;然后每次形成训练集时使用所有的正样本( 100 条)和随机抽取的负样本( 100 条)形成新的数据集。如此反复可以得到 100 个训练集和对应的训练模型。这种解决问题的思路类似于随机森林。在随机森林中,虽然每个小决策树的分类能力很弱,但是通过大量的 “小树 ”组合形成的 “森林 ”具有良好的模型预测能力。如果计算资源充足,并且对于模型的时效性要求不高,这种方法比较合适。
上述几种方法都是基于数据行的操作,通过多种途径可使不同类别的样本数据行记录均衡。除此以外,还可以考虑使用或辅助基于列的特征选择方法。一般情况下,样本不均衡也会导致特征分布不均衡,但如果小类别样本量具有一定的规模,那么意味着其特征值的分布较为均衡,可通过选择具有显著型的特征配合参与解决样本不均衡问题,也能在一定程度上提高模型效果。上述几种方法的思路都是基于分类问题的。实际上,这种从大规模数据中寻找罕见数据的情况,也可以使用非监督式的学习方法,例如使用 One-class SVM 进行异常检测。分类是监督式方法,前期是基于带有标签( Label )的数据进行分类预测的;而采用非监督式方法,则是使用除了标签以外的其他特征进行模型拟合的,这样也能得到异常数据记录。所以,要解决异常检测类的问题,先是考虑整体思路,再考虑方法模型。
本示例中,我们主要使用的是一个新的专门用于不平衡数据处理的Python 包imbalan-ced-learn ,读者需要先在系统终端的命令行使用 pipinstall imbalanced-learn 进行安装。安装成功后,在 Python 或IPython 命令行窗口通过使用 import imblearn (注意导入的库名)检查安装是否正确,除此以外,我们还会使用 sklearn 的SVM 在算法中通过调整类别权重来处理样本不均衡问题。
import pandas as pd
from imblearn.over_sampling import SMOTE # 过抽样处理库 SMOTE
from imblearn.under_sampling import RandomUnderSampler # 欠抽样处理库 Random-UnderSampler
from sklearn.svm import SVC # SVM 中的分类算法 SVC
from imblearn.ensemble import EasyEnsemble # 简单集成方法 EasyEnsemble
# 导入数据文件
df = pd.read_table('data2.txt', sep=' ', names=['col1', 'col2', 'col3', 'col4', 'col5', 'label']) # 读取数据文件
x = df.iloc[:, :-1] # 切片,得到输入 x
y = df.iloc[:, -1] # 切片,得到标签 y
groupby_data_orgianl = df.groupby('label').count() # 对label 做分类汇总
print (groupby_data_orgianl) # 打印输出原始数据集样本
# 使用 SMOTE 方法进行过抽样处理
model_smote = SMOTE() # 建立 SMOTE 模型对象
x_smote_resampled, y_smote_resampled = model_smote.fit_sample(x, y) # 输入数据并作过抽样处理
x_smote_resampled = pd.DataFrame(x_smote_resampled, columns=['col1', 'col2', 'col3', 'col4', 'col5']) # 将数据转换为数据框并命名列名
y_smote_resampled = pd.DataFrame(y_smote_resampled, columns=['label']) # 将数据转换为数据框并命名列名
smote_resampled = pd.concat([x_smote_resampled, y_smote_resampled], axis=1) # 按列合并数据框
groupby_data_smote = smote_resampled.groupby('label').count() # 对label 做分类汇总
print (groupby_data_smote) # 打印输出经过 SMOTE 处理后的数据集样本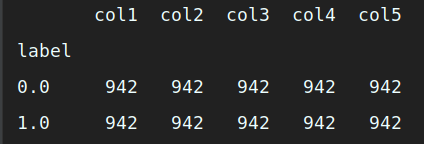
# 使用 RandomUnderSampler 方法进行欠抽样处理
model_RandomUnderSampler = RandomUnderSampler() # 建立 RandomUnderSampler 模型对象
x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled = model_RandomUnderSampler.fit_sample(x,y) # 输入数据并进行欠抽样处理
x_RandomUnderSampler_resampled = pd.DataFrame(x_RandomUnderSampler_resampled,columns=['col1','col2','col3','col4','col5']) # 将数据转换为数据框并命名列名
y_RandomUnderSampler_resampled = pd.DataFrame(y_RandomUnderSampler_resampled, columns=['label']) # 将数据转换为数据框并命名列名
RandomUnderSampler_resampled = pd.concat([x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled], axis = 1) # 按列合并数据框
groupby_data_RandomUnderSampler = RandomUnderSampler_resampled.groupby('label').count() # 对label 做分类汇总
print (groupby_data_RandomUnderSampler) # 打印输出经过 RandomUnderSampler 处理后的数据集样本分类分布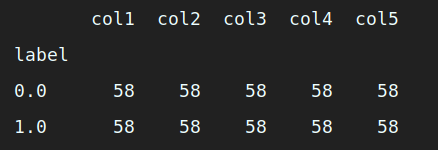
# 使用 SVM 的权重调节处理不均衡样本 model_svm = SVC(class_weight='balanced') # 创建 SVC 模型对象并指定类别权重 model_svm.fit(x, y) # 输入 x和y并训练模型 # 使用集成方法 EasyEnsemble 处理不均衡样本 model_EasyEnsemble = EasyEnsemble() # 建立 EasyEnsemble 模型对象 x_EasyEnsemble_resampled, y_EasyEnsemble_resampled = model_EasyEnsemble.fit_sample (x, y) # 输入数据并应用集成方法处理 print (x_EasyEnsemble_resampled.shape) # 打印输出集成方法处理后的 x样本集概况 print (y_EasyEnsemble_resampled.shape) # 打印输出集成方法处理后的 y标签集概况
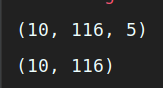
# 抽取其中一份数据做审查
index_num = 1 # 设置抽样样本集索引
x_EasyEnsemble_resampled_t = pd.DataFrame(x_EasyEnsemble_resampled[index_num],columns=['col1','col2','col3','col4','col5']) # 将数据转换为数据框并命名列名
y_EasyEnsemble_resampled_t = pd.DataFrame(y_EasyEnsemble_resampled[index_num],columns=['label']) # 将数据转换为数据框并命名列名
EasyEnsemble_resampled = pd.concat([x_EasyEnsemble_resampled_t, y_EasyEnsemble_resampled_t], axis = 1) # 按列合并数据框
groupby_data_EasyEnsemble = EasyEnsemble_resampled.groupby('label').count() # 对label 做分类汇总
print (groupby_data_EasyEnsemble) # 打印输出经过 EasyEnsemble 处理后的数据集样本
本小节示例中,主要用了以下几个知识点:
·通过 Pandas 的read_table 方法读取文本数据文件,并指定列名;
·对数据框做切片处理;
·通过 Pandas 提供的 groupby ()方法配合 count ()做分类汇总;
·使用 imblearn.over_sampling 中的 SMOTE 做过抽样处理;
·使用 imblearn.under_sampling 中的 RandomUnderSampler 做欠抽样处理;
·使用 imblearn.ensemble 中的 EasyEnsemble 做集成处理;
·使用 sklearn.svm 中的 SVC 自动调整算法对不同类别的权重设置。


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago