
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
第 3 章 11 条数据化运营不得不知道的数据预处理经验二
分类数据和顺序数据是常见的数据类型,这些值主要集中在围绕数据实体的属性和描述的相关字段和变量中。
的数据可以分为两类:
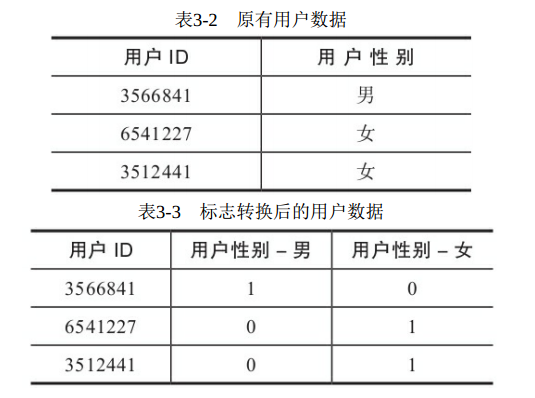
1 )分类数据:分类数据指某些数据属性只能归于某一类别的非数值型数据,例如性别中的男、女就是分类数据。分类数据中的值没有明显的高、低、大、小等包含等级、顺序、排序、好坏等逻辑的划分,只是用来区分两个或多个具有相同或相当价值的属性。例如:性别中的男和女,颜色中的红、黄和蓝,它们都是相同衡量维度上的不同属性分类而已。
2 )顺序数据:顺序数据只能归于某一有序类别的非数值型数据,例如用户的价值度分为高、中、低,学历分为博士、研究生、学士,这些都属于顺序数据。在顺序数据中,有明显的排序规律和逻辑层次的划分。例如:高价值的用户就是比低价值的用户价值高(业务定义该分类时已经赋予了这样的价值含义)。
分类数据和顺序数据要参与模型计算,通常都会转化为数值型数据。当然,某些算法是允许这些数据直接参与计算的,例如分类算法中的决策树、关联规则等。将非数值型数据转换为数值型数据的最佳方法是:将所有分类或顺序变量的值域从一列多值的形态转换为多列只包含真值的形态,其中的真值可通过 True 、 False 或 0 、 1 的方式来表示。这种标志转换的方法有时候也称为真值转换。
为什么不能直接用数字来表示不同的分类和顺序数据,而一定要做标志转换?这是因为在用数字直接表示分类和顺序变量的过程中,无法准确还原不同类别信息之间的差异和相互关联性。
3 代码实操: Python 标志转换
将模拟有两列数据分别出现分类数据和顺序数据的情况,并通过自定义代码以及 sklearn 代码分别进行标志转换。
import pandas as pd # 导入 pandas 库
from sklearn.preprocessing import OneHotEncoder # 导入 OneHotEncoder 库
# 生成数据
df = pd.DataFrame({'id': [3566841, 6541227, 3512441], 'sex': ['male', 'Female', 'Female'], 'level': ['high', 'low', 'middle']})
print (df) # 打印输出原始数据框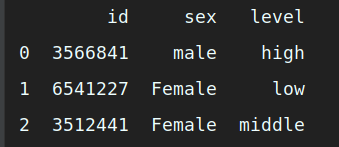
注意:虽然在 Python 中可以通过一定的方法来处理中文,但鉴于我们用到的库基本都是外国人开发,对中文的支持不太好,所以不建议在程序中直接使用中文进行计算和建模,除非是基于文本的自然语言和文本挖掘等直接面向中文的主题建模。
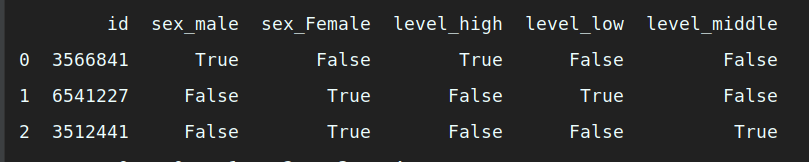
# 自定义转换主过程 df_new = df.copy() # 复制一份新的数据框用来存储转换结果 for col_num, col_name in enumerate(df): # 循环读出每个列的索引值和列名 col_data = df[col_name] # 获得每列数据 col_dtype = col_data.dtype # 获得每列 dtype 类型 if col_dtype == 'object': # 如果 dtype 类型是 object (非数值型),执行条件 df_new = df_new.drop(col_name, 1) # 删除 df 数据框中要进行标志转换的列 value_sets = col_data.unique() # 获取分类和顺序变量的唯一值域 for value_unique in value_sets: # 读取分类和顺序变量中的每个值 col_name_new = col_name + '_' + value_unique # 创建新的列名,使用 “ 原标题 + 值 ” 的方式命名 col_tmp = df.iloc[:, col_num] # 获取原始数据列 new_col = (col_tmp == value_unique) # 将原始数据列与每个值进行比较,相同为 True ,否则为 False df_new[col_name_new] = new_col # 为最终结果集增加新列值 print (df_new) # 打印输出转换后的数据框
# 使用 sklearn 进行标志转换
df2 = pd.DataFrame({'id': [3566841, 6541227, 3512441], 'sex': [1, 2, 2], 'level': [3, 1, 2]})
id_data = df2.values[:, :1] # 获得 ID 列
transform_data = df2.values[:, 1:] # 指定要转换的列
enc = OneHotEncoder() # 建立模型对象
df2_new = enc.fit_transform(transform_data).toarray() # 标志转换
df2_all = pd.concat((pd.DataFrame(id_data), pd.DataFrame(df2_new)), axis=1) # 组合为数据框
print (df2_all) # 打印输出转换后的数据框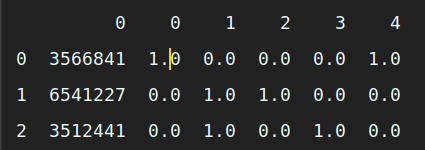
需要考虑的关键点是:
· 如何判断要转换的数据是分类或顺序数据。
· 要在结果数据框中不断删除被转换的原始列并新增转换后的数据列,以防止数据列的重复。
主要用了以下几个知识点:
· 通过 pd.DataFrame 构建新的数据框;
· 通过 Pandas 中的 df[col_name] 和 iloc[] 进行数据切片;
· 通过 Pandas 中的 drop ()方法删除特定列,当然也可以用于删除行;
· 通过 Pandas 的 dtype 获得对象的 dtype 类型, df.dtypes 也能实现所有对象的类型;
· 通过 unique ()方法获得唯一值;
· 通过字符串组合(示例中直接使用的 + )创建一个新的字符串;
· 直接使用矩阵( Series )对象而无须遍历每个值进行矩阵比较和数值计算;
· 通过 Pandas 的 df_new[col_name_new] 方法直接新增列值。


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago