
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
第 2 章 数据化运营的数据来源一
大多数情况下, txt (任意指定分隔符)、 cvs (以逗号分隔的数据文件)、 tsv (以 tab 制表符分隔的数据文件)是最常用的数据文件格式。当数据文件大小在百兆级别以下时,可以使用 Excel 等工具打开;数据文件大小在百兆级别时,推荐使用 Notepad 打开;当数据文件大小在 G 级别时,推荐使用 UltraEdit 打开。
数据库的主要应用包括数据的定义、存储、增加、删除、更新、查询等事务型工作,数据传输、同步、抽取、转换、加载等数据清洗工作,数据计算、关联查询、 OLAP 等分析型工作以及数据权限控制、数据质量维护、异构数据库和多系统通信交互等工作。数据库按类型分为关系型数据库和非关系型数据库(又称 NoSQL 数据库)。关系型数据库在企业中非常常见,在传统企业中更为流行,常见的关系型数据库包括 DB2 、 Sybase 、 Oracle 、 PostgreSQL 、 SQLServer 、 MySQL 等;非关系型数据库随着企业经营场景的多样化以及大数据场景的出现,根据应用场景和结构分为以下几类:
· 面向高性能并发读写的键值( Key-Value )数据库:优点是具有极高的并发读写性能、查找速度快,典型代表是 Redis 、 Tokyo Cabinet 、Voldemort 。
· 面向海量文档的文档数据库:优点是对数据要求不严格,无须提前定义和维护表结构,典型代表为 MongoDB 、 CouchDB 。
· 面向可扩展性的列式数据库:优点是查找速度快,可扩展性强,通过分布式扩展来适应数据量的增加以及数据结构的变化,典型代表是Cassandra 、 HBase 、 Riak 。
· 面向图结构的图形数据库( Graph Database ):优点是利用图结构相关算法,满足特定的数据计算需求,例如最短路径搜寻、关系查询等,典型代表是 Neo4J 、 InfoGrid 、 Infinite Graph 。
API ( Application Programming Interface )是应用程序编程接口,数据化运营中的 API 通常分为服务型 API 和数据型 API 。服务型 API 可以基于预定义的规则,通过调用 API 实现特定功能。例如,通过调用百度地图 JavaScript API 可以在网站中构建功能丰富、交互性强的地图应用,这种 API 下输入的是地理位置数据,从 API 获得的输出是可视化地图(服务 / 功能)。数据型 API 则通过特定的语法,通过向服务器发送数据请求,返回特定格式的数据(或数据文件)。例如,通过向 Google Analytics 的Analytics Reporting API V4 发送请求来获得符合特定条件的数据记录。API 广泛应用于企业内部和外部多系统和平台交互。 API 返回的数据格式,大多数情况下是 JSON 、 XML 格式。
流式数据指的是实时或接近实时处理的大数据流。常见的流式数据处理使用 Spark 、 Storm 和 Samza 等框架,能在毫秒到秒之间完成作业,用于处理时效性较强的场景,例如在线个性化推荐系统、网站用户实时行为采集和分析、物联网机器日志实时分析、金融实时消费反欺诈、实时异常人员识别等,应用领域集中在实时性较强的互联网、移动互联网、物联网等。按照数据对象来区别,流式数据可分为两类:第一类是用户行为数据流 。用户行为数据流是围绕 “ 人 ” 产生的数据流,包括用户在网站和 APP 内部因浏览、搜索、评论、分享、交易以及在外部的微博、微信中操作而产生的数据流。用户行为数据流采集平台可分为 Web 站、移动站和 APP (包含 iOS 、 Android 、 Windows 等)应用。 Web 站及基于 HTML5 开发的移动应用都支持 JS 脚本采集,较早开发的不支持 JS 的 Wap 站(现在基本上很少)则采用 NoScript 方法,即一个像素的硬图片实现数据跟踪。 SDK 是针对 APP 提供数据采集的特定方法和框架。这三种方法可以实现目前所有线上用户行为数据采集的需求。第二类是机器数据流 。机器数据流是围绕 “ 物 ” 产生的数据流,包括从机器的生产、制造、应用、监控和管理等过程中产生的所有数据,例如机器运行日志、传感器监控数据、音频采集器数据、监控图像和视频、 GPS 地理数据等。
外部公开数据指公开的任意第三方都能获取的数据。数据化运营所需的外部公开数据来源渠道众多,常见的包括:
· 政府和相关机构提供的公开数据,例如国家统计局提供的月度 CPI数据;
· 竞争对手主动公开的数据,例如通过新闻发布会、网络宣传等发布的数据;
· 行业协会或相关平台组织提供的统计、资讯数据,例如艾瑞提供的行业研究报告发布的数据;
· 第三方的组织或个人披露的与企业运营相关的数据,例如有关竞争对手的供应商、客户等数据。
其他,在某些场景下,企业数据化运营所用数据还会有其他来源,例如通过调研问卷获得的有关产品、客户等方面的数据,从第三方平台直接购买的数据,通过与其他厂商合作所得交互数据等。由于这些场景比较少,并且不是企业主流的数据获取来源,在此不作过多阐述。
使用 Python 获取数据,目前主要的方法集中在文本文件、 Excel 文件、关系型和非关系型数据库、 API 、网页等方面。
1. 使用 read 、 readline 、 readlines 读取数据
Python 可以读取任意格式的文本数据,使用 Python 读取文本数据的基本步骤是:
1 )定义数据文件;file_name = 'd:/python_data/data/text.txt'
2 )获取文件对象;file object = open(name [, mode][, buffering])
参数:
·name :要读取的文件名称,即上一个环节定义的 file_name ,必填。
·mode :打开文件的模式,选填,在实际应用中, r 、 r+ 、 w 、 w+ 、a 、 a+ 是使用最多的模式。
·buffering :文件所需的缓冲区大小,选填; 0 表示无缓冲, 1 表示线路缓冲。
返回:通过 open 函数会创建一个文件对象( file object )。file_object = open('text.txt')
Python 基于文件对象的读取分为 3 种方法:read,readline,readlines
在实际应用中, read 方法和 readlines 方法比较常用,而且二者都能读取全部文件中的数据。二者的区别只是返回的数据类型不同,前者返回字符串,适用于所有行都是完整句子的文本文件,例如大段文字信息;后者返回列表,适用于每行是一个单独的数据记录,例如日志信息。不同的读取方法会直接影响后续基于内容的处理应用; readline 由于每次只读取一行数据,因此通常需要配合 seek 、 next 等指针操作才能完整遍历读取所有数据记录。
3 )读取文件内容;
4 )关闭文件对象。
每次使用完数据对象之后,需要关闭数据对象。方法是file_object.close ()。
关于 “ 最佳 ” 方法其实没有固定定义,因此所谓的最佳方法往往跟以
下具体因素有关:
· 数据源情况: 数据源中不同的字段类型首先会制约读取方法的选择,文本、数值、二进制数据都有各自的适应方法约束。
· 数据处理目标: 读取数据往往是第一步,后续会涉及数据探索、预处理、统计分析等复杂过程,这些复杂过程需要用到哪些方法一定程度上都会受数据源的读取影响,影响最多的点包括格式转换、类型转换、异常值处理、分类汇总等。
· 模型数据要求: 不同的模型对于数据格式的要求是不同的,应用到实际中不同的工具对于数据的表示方法也有所差异。
· “ 手感 ” 最好的方法: 很多时候,最佳方法往往是对哪个或哪些方法最熟悉,这些所谓的 “ 手感 ” 最好的方法便是最佳方法。
现有的 Excel 分为两种格式: xls ( Excel 97-2003 )和 xlsx ( Excel2007 及以上)。
Python 处理 Excel 文件主要是第三方模块库 xlrd 、 xlwt 、 pyexcel-xls 、
xluntils 和 pyExcel-erator ,以及 win32com 和 openpyxl 模块,此外 Pandas 中也带有可以读取 Excel 文件的模块( read_excel )。
import xlrd # 导入库
# 打开文件
xlsx = xlrd.open_workbook('demo.xlsx')
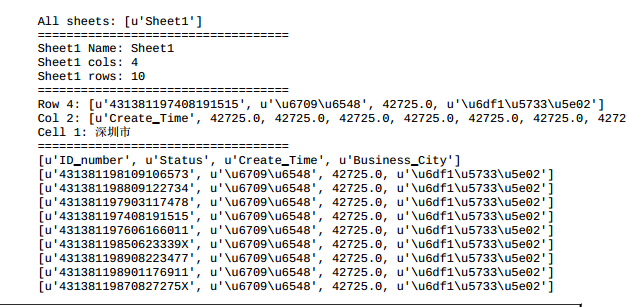
# 查看所有 sheet 列表
print ('All sheets: %s' % xlsx.sheet_names())
print ('===================================') # 内容分割线
# 查看 sheet1 的数据概况
sheet1 = xlsx.sheets()[0] # 获得第一张 sheet ,索引从 0 开始
sheet1_name = sheet1.name # 获得名称
sheet1_cols = sheet1.ncols # 获得列数
sheet1_nrows = sheet1.nrows # 获得行数
print ('Sheet1 Name: %s\nSheet1 cols: %s\nSheet1 rows: %s') % (sheet1_name, sheet1_cols, sheet1_nrows)
print ('===================================') # 内容分割线
# 查看 sheet1 的特定切片数据
sheet1_nrows4 = sheet1.row_values(4) # 获得第 4 行数据
sheet1_cols2 = sheet1.col_values(2) # 获得第 2 列数据
cell23 = sheet1.row(2)[3].value # 查看第 3 行第 4 列数据
print ('Row 4: %s\nCol 2: %s\nCell 1: %s\n' % (sheet1_nrows4, sheet1_cols2, cell23))
print ('===================================') # 内容分割线
# 查看 sheet1 的数据明细
for i in range(sheet1_nrows): # 逐行打印 sheet1 数据
print (sheet1.row_values(i))
1 )只查询前 N 条数据而非全部数据行记录。
示例:只查询前 100 条数据记录。
SELECT * FROM `order` LIMIT 100;
要从第 11 条开始取,取 10 条可以写为
SELECT * FROM `order` LIMIT 11, 10;
2 )只查询特定列(而非全部列)数据。
示例:只查询 total_amount 和 order_id 两列数据。
SELECT total_amount, order_id from `order`;
3 )查询特定列去重后的数据。
示例:查询针对 user_id 去重后的数据。
SELECT DISTINCT user_id FROM `order`;
4 )查询带有 1 个条件的数据。
示例:查询 total_amount<100 的所有数据。
SELECT * FROM `order` WHERE total_amount < 100;
5 )查询带有多个条件(同时满足)的数据。
示例:查询 total_amount<100 且 status 为 REMOVED 的所有数据。
SELECT * FROM `order` WHERE total_amount < 100 and `status` = 'REMOVED';
6 )查询带有多个条件(满足任意一个)的数据。
示例:查询 total_amount<100 或 status 为 REMOVED 的所有数据。
SELECT * FROM `order` WHERE total_amount < 100 or `status` = 'REMOVED';
7 )查询特定条件值在某个值域范围内的数据。
SELECT * FROM `order` WHERE `status` in ('REMOVED','NO_PENDING_ACTION','PENDING_ORDER_CONFIRM');
8 )使用正则表达式查询具有复杂条件的数据。
示例:查询 user_id 以 106 开头且 order_id 包含 04 的所有订单数据。
SELECT * FROM `order` WHERE user_id LIKE '103%' and order_id LIKE '%04%';
· 以特定字符开头: ' 字符串 %' ,例如 'ABD%' 表示以 ABD 开头的所有匹配;
· 以特定字符结尾: '% 字符串 ' ,例如 '%ABD' 表示以 ABD 结尾的所有匹配;
· 包含特定字符: '% 字符串 %' ,例如 '%ABD%' 表示包含 ABD 的所有匹配。
9 )将查询到的数据倒叙排列。
示例:将 total_amount 金额在 10 ~ 100 之间的所有数据按照订单 ID 倒叙排序。
SELECT * FROM `order` WHERE 10 < total_amount < 100 ORDER BY order_id DESC;
10 )查询指定列中不包含空值的所有数据。
示例:查询 order_id 不为空的所有数据。
SELECT * FROM `order` WHERE order_id IS NOT NULL;
上述案例只是展示了如何取数,更多情况下,我们会配合特定函数和方法做数据计算、整合和探索性分析,例如:
· 使用 MySQL 聚合函数求算术平均值、计数、求最大 / 最小值、做分类汇总等;
· 使用 MySQL 数学函数,用来求绝对值、进行对数计算、求平方根等;
· 使用 MySQL 字符串函数进行字符串分割、组合、截取、匹配、处理等;
· 使用 MySQL 的日期函数进行日期获取、转换、处理等;
· 使用 MySQL 将多个表( 2 个或 2 个以上)数据进行关联、匹配和整合。
从非关系型数据库 MongoDB 读取运营数据


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago