
Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
PYTHON实战——用户消费分析二
''' 用户消费行为
用户第一次消费
用户最后一次消费
新老客户消费比
多少用户仅消费一次
每月新客占比
用户分层
RFM
新,老,活跃,回流,流失
用户购买周期
用户周期描述
用户消费周期分布
用户生命周期
用户生命周期描述
用户生命周期分布
'''
group_user.min().order_dt.value_counts().plot() plt.show() # 用户第一次购买分布,集中在前三个月 # 其中在2.11至2.25有一次剧烈的波动

group_user.max().order_dt.value_counts().plot() plt.show() # 用户最后一次购买的分布比第一次分布广 # 大部分最后一次购买,集中在前三月,说明有很多用户购买了一次后就不再进行购买

user_life = group_user.order_dt.agg(['min', 'max']) print(user_life.head())

print((user_life['min'] == user_life['max']).value_counts()) # 有一半的用户只消费了一次

rfm = txt.pivot_table(index='user_id',
values=['order_product', 'order_amount', 'order_dt'],
aggfunc={'order_dt': 'max',
'order_amount': 'sum',
'order_product': 'sum'}
)
print(rfm.head())
rfm['R'] = -(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1, 'D')
rfm.rename(columns={'order_product': 'F', 'order_amount': 'M'}, inplace=True)
def rfm_func(x):
level = x.apply(lambda x: '1' if x >= 1 else '0')
label = level.R + level.F + level.M
d = {
'111': '重要价值客户',
'011': '重要保持客户',
'101': '重要发展客户',
'001': '重要挽留客户',
'110': '一般价值客户',
'010': '一般保持客户',
'100': '一般发展客户',
'000': '一般挽留客户',
}
result = d[label]
return resultrfm = rfm[rfm['F'] < 200]
rfm['label'] = rfm[['R', 'F', 'M']].apply(lambda x: x - x.mean()).apply(rfm_func, axis=1)
print(rfm.head())
rfm.loc[rfm.label == '重要价值客户', 'color'] = 'g'
rfm.loc[(rfm.label == '一般价值客户'), 'color'] = 'r'
rfm.loc[(rfm.label == '一般保持客户'), 'color'] = 'b'
rfm.loc[(rfm.label == '一般发展客户'), 'color'] = 'c'
rfm.loc[(rfm.label == '一般挽留客户'), 'color'] = 'm'
rfm.loc[(rfm.label == '重要挽留客户'), 'color'] = 'k'
rfm.loc[(rfm.label == '重要保持客户'), 'color'] = 'y'
rfm.loc[(rfm.label == '重要发展客户'), 'color'] = 'w'
#
rfm.plot.scatter('F', 'R', c=rfm.color)
plt.show()
print(rfm.groupby('label').sum())
print(rfm.groupby('label').count())
pivoted_counts = txt.pivot_table(index='user_id',
columns='month',
values='order_dt',
aggfunc='count').fillna(0)
df_purchase = pivoted_counts.applymap(lambda x: 1 if x > 0 else 0)
def active_status(data):
status = []
# 18个月
for i in range(18):
# 本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i - 1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 本月消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i - 1] == 'unactive':
status.append('return')
elif status[i - 1] == 'unreg':
status.append('new')
else:
status.append('active')
return statuspd.set_option('display.max_columns', None)
purchase_stats = df_purchase.apply(active_status, axis=1)
print(purchase_stats.head())
purchase_stats_ct = purchase_stats.replace('unreg', np.NaN).apply(lambda x: pd.value_counts(x))
print(purchase_stats_ct)
purchase_stats_ct.fillna(0).T.head() purchase_stats_ct.fillna(0).T.plot.area() plt.show()
I3M(CAIJGE`4U9I4HD($J7_20200610184119_903.png)
# 各部分占比占比 purchase_stats_ct.fillna(0).T.apply(lambda x: x / x.sum(), axis=1) ''' 由上表可知,每月的用户消费状态变化 活跃用户,持续消费的用户,对应的使消费运营的质量 回流用户,之前不消费本月才消费,对应的使换回运营 不活跃用户,对应的是流失 ''' order_diff = group_user.apply(lambda x: x.order_dt - x.order_dt.shift()) print(order_diff.head()) # 错位函数 shift() 向下平移一位 print(order_diff.describe()) # 每一天的分布图 (order_diff / np.timedelta64(1, 'D')).hist(bins=20) plt.show()
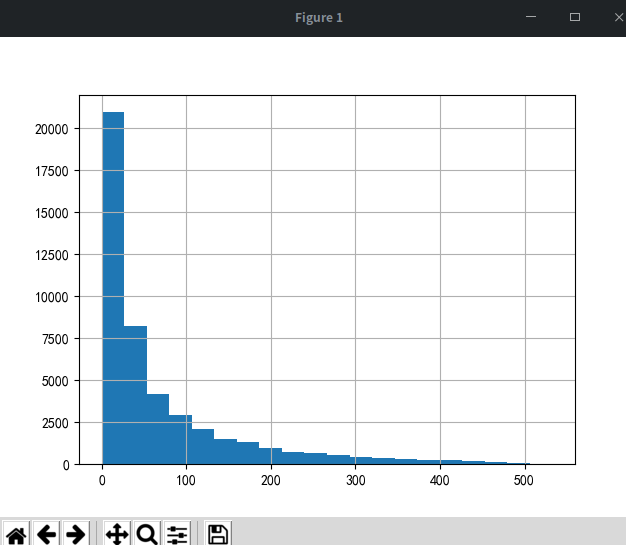
''' 订单周期呈指数分布 用户的平均购买周期为68 绝大部分用户的购买周期都低于100天 ''' # 第一和最后一次消费 user_life = group_user.order_dt.agg(['min', 'max']) print((user_life['max'] - user_life['min']).describe()) ((user_life['max'] - user_life['min']) / np.timedelta64(1, 'D')).hist(bins=20) plt.show()
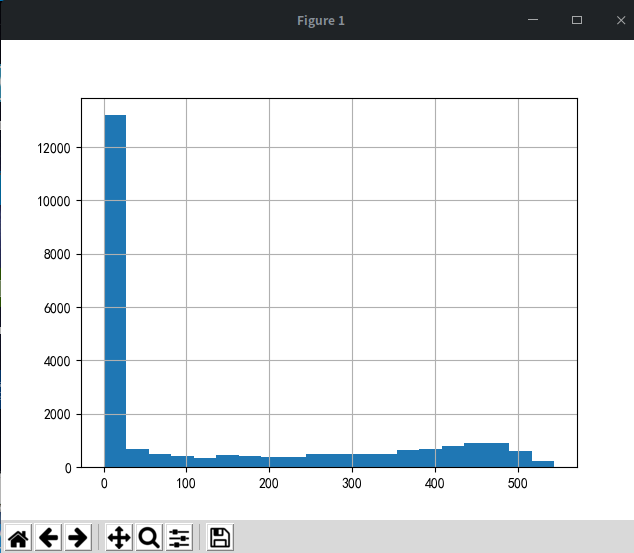
# 提取次数 把0过滤掉 u_1 = (user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1, 'D') u_1[u_1 > 0].hist(bins=40) plt.show()
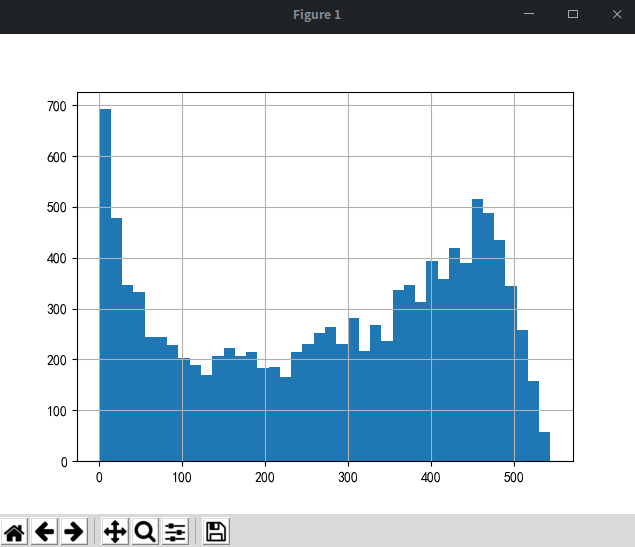
'''
用户的生命周期受只购买一次的用户影响比较厉害
用户均消费134天,中位数仅0天
'''
'''
回购率和复购率分析
复购率
自然月内,购买次数的用户占比
回购率
曾经购买过的用户在某一时期内的再次购买的占比
'''
pivoted_counts = txt.pivot_table(index='user_id', columns='month', values='order_dt', aggfunc='count').fillna(0) # else嵌套 purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0) (purchase_r.sum() / purchase_r.count()).plot(figsize=(10, 4)) plt.show()

'''
复购率在20%左右,前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低
'''
def purchase_back(data): status = [] for i in range(17): if data[i] == 1: if data[i + 1] == 1: status.append(1) if data[i + 1] == 0: status.append(0) else: status.append(0) status.append(np.NaN) return status df_purchase = pivoted_counts.applymap(lambda x: 1 if x > 0 else 0) purchase_b = df_purchase.apply(purchase_back, axis=1) print(purchase_b.head())

(purchase_b.sum() / purchase_b.count()).plot(figsize=(10, 4)) plt.show()


Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Sed ac lorem felis. Ut in odio lorem. Quisque magna dui, maximus ut commodo sed, vestibulum ac nibh. Aenean a tortor in sem tempus auctor
December 4, 2020 at 3:12 pm

Donec in ullamcorper quam. Aenean vel nibh eu magna gravida fermentum. Praesent eget nisi pulvinar, sollicitudin eros vitae, tristique odio.
December 4, 2020 at 3:12 pm


我是 s enim interduante quis metus. Duis porta ornare nulla ut bibendum
Rosie
6 minutes ago